
Ca multe alte estimări, la trecerea de la eșantion la populație putem să convertim estimările parametrilor descrise cu o singură valoare în secțiunile precedente în intervale, care permit statisticianului să transmită nu doar valoarea cea mai probabilă, dar și o măsură a incertitudinii din jurul acelei valori. În plus, vom defini intervale de încredere pentru valorile previzionate de modelul de regresie.
Termeni generali privind intervalele de încredere
Intervalul de încredere (eng. confidence interval) este modul în care statisticienii descriu o estimație, împreună cu o măsură a incertitudinii din jurul acelei estimații. Un statistician va dispune de un singur eșantion, și deci va putea calcula o singură estimație, și un singur interval de încredere. Acel interval de încredere va fi însă având în vedere numărul extrem de mare de eșantioane care poate fi creat cu aceeași metodă de eșantionare, măsurare și analiză. Mai precis, intervalul de încredere este descris cu un procentaj de încredere, numit nivel de încredere. De exemplu, vorbim de interval de încredere 95%, situație în care calculele sunt concepute în așa fel încât, din multitudinea de eșantioane obținute prin selecție similară, 95% vor conține și valoarea reală a parametrului.
De regulă, intervalele de încredere se calculează prin adunarea la, și scăderea de la, valoarea cea mai probabilă (estimația punctuală) a unei erori limită de reprezentare (zisă și eroare limită acceptabilă, sau, simplu, eroare limită; margin of error). Deci intervalul de încredere va fi intervalul (Epunctuală – ELR … Epunctuală + ELR). Eroarea limită de reprezentare este produsul a doi factori:
- eroarea standard (zisă eroare tipică, abatere standard; eng. standard error) cuantificând variabilitatea valorilor din eșantion și
- coeficientul corespunzător nivelului de încredere (uneori coeficient de încredere; eng. confidence coefficient), ce depinde exclusiv de tipul de variabilitate previzionat de teorie (unul corespunzător distribuției normale, altul pentru distribuție t, altul pentru distribuție χ²) și de nivelul de încredere.
De exemplu, probabil știați că media eșantionului X̄ poate fi transformată în interval de încredere prin adunare și scădere, la acea tendință centrală, a unei erori limită calculate cu \(1,96 \times \frac {s}{\sqrt{n}}\). Partea \(\frac {s}{\sqrt{n}}\) este (aproximativ) eroarea standard a mediei, dar de ce 1,96?
Termeni relevanți privind distribuțiile teoretice
Regiuni importante și calcularea ariei lor
Distribuția normală este cel mai cunoscut exemplu de distribuție teoretică, fiind distribuția din care ați derivat intervalele de încredere pentru mediile de eșantioane, modul în care se repartizează mediile de eșantion, și repartiția bilelor din aparatul lui Galton:
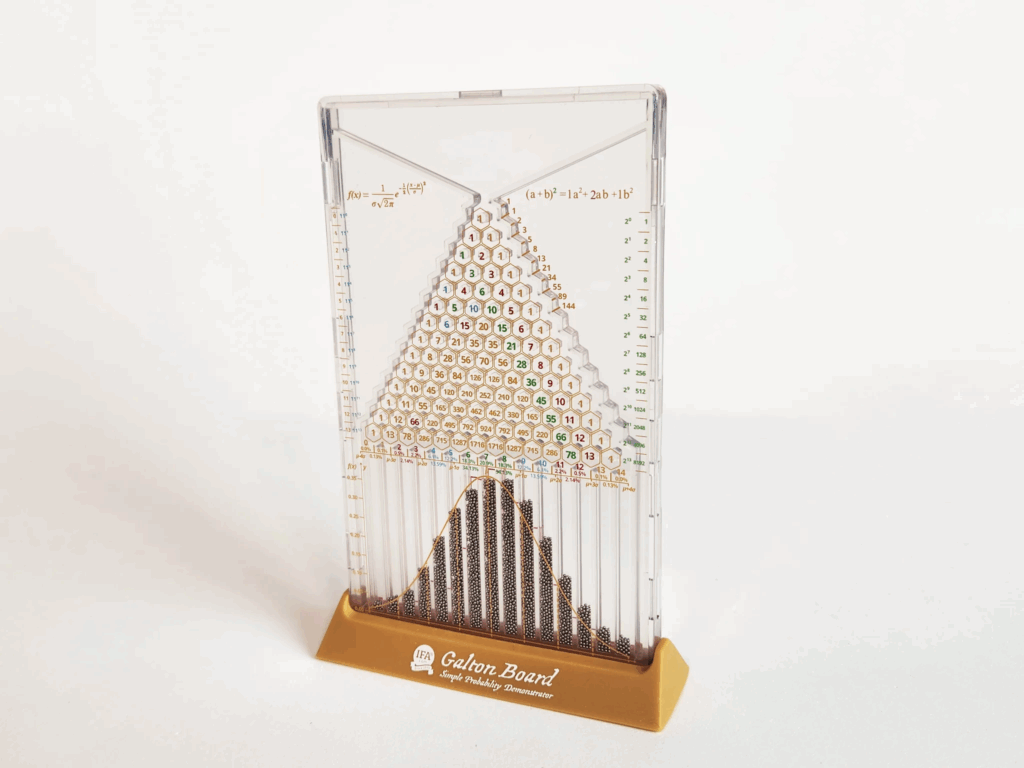
Dacă am imagina pe marginea inferioară a aparatului lui Galton o axă Oz, centrată pe mijlocul cel mai comun al distribuției acelor bile, și gradată în erori standard, am putea previziona, pentru orice poziție de pe axa Oz, câte bile se vor afla la stânga acelei poziții, și câte la dreapta. Proporția celor din stânga, descrisă ca număr subunitar, ar fi aproximativ \( \frac{1}{2} + \frac{1}{\sqrt{2\pi}} \sum_{n=0}^{\infty} \frac{(-1)^n z^{2n+1}}{n! (2n+1)}\), unde z ar fi poziția unde am face partiționarea.
Nu trebuie reținută formula, valorile sale pentru diferite valori ale lui z fiind disponibile în orice aplicație statistică. Notăm proporția de la stânga (regiunea albastră) cu CDF (cumulative distribution function), și cea de la dreapta (regiunea roz) cu CCDF (complementary CDF). Mutați cursorul pentru a ajusta poziția ce le separă:
În manualele de statistică române, germane sau ruse, veți mai regăsi o proporție, cea a cazurilor de la mijlocul distribuției până la acel prag de partiționare, numită funcție Gauss-Laplace (notată GaussL aici, hașurată):
Exemplele de mai sus arată că pentru orice z, CDF(z) + CCDF(z) = 1, iar GL(z) = CDF(z) – ½.
În afara acestor regiuni, statisticienii mai practică partiționări în care este combinat un prag z cu imaginea sa în oglindă. Regiunea cuprinsă între cele două limite va fi descrisă ca fiind cea a cazurilor comune sau chiar normale (regiunea centrală, verde), în timp ce cele două regiuni (cozi, cu roșu) rămase în afară vor fi considerate cazuri rare sau uneori anormale.
Cazurile extreme vor fi în proporție de 2 × CCDF, iar cele non-extreme vor fi 1 – 2×CCDF.
În mod normal, nu va fi necesar să învățați pe de rost valori ale acestor funcții.
- La examenele scrise veți primi propoziții de forma “Φ(z=2) = 0,477”. În România (Germania, Rusia etc), Φ desemnează funcția Gauss-Laplace, în timp ce în lumea anglofonă Φ reprezintă CDF (sic!).
- La examenele practice puteți obține CDF din softul statistic. De exemplu, în Excel, pentru același z=2 putem obține CDF cu NORM.DIST(2, 0, 1, TRUE) care va returna 0,977.
Pentru completitudine, includem câteva valori importante:
| z | Proporția cazurilor centrale, dintre -z și z | Proporția cazurilor extreme, mai departe de -z la stânga sau mai departe de z la dreapta | CCDF | CDF |
| 1 | 0.6827 | 0.3173 | 0.1587 | 0.8413 |
| 2 | 0.9545 | 0.0455 | 0.0228 | 0.9772 |
| 3 | 0.9973 | 0.0027 | 0.00135 | 0.99865 |
Calcularea valorii z, dată fiind o arie a unei regiuni din distribuția normală
Intervalele de încredere necesită transformarea inversă. De exemplu, un interval de încredere 95% pentru mediilor unor eșantioane mari este cel definit de partiționarea spectrului infinit al valorilor posibile în submulțimea centrală, cu 95% cele mai comune cazuri, și cele două cozi cu valori extreme, păstrând restul de 5% din cazuri.
Pentru intervale de încredere, numim proporția cazurilor extreme, pe care suntem dispuși să le ratăm, nivel de semnificație, notat α. Proporția α este scrisă ca număr subunitar (nu ca procent!). Aici, și pentru orice intervale de încredere 95%, α este 0,05.
Deoarece cozile sunt simetrice și egale ca arie, delimitarea cazurilor extreme de cele nonextreme va fi dată de două poziții de pe axa orizontală, -z și z, a căror valoare este aceea care face ca CCDF(z) să fie α/2, aici 0,025. Ne este deci necesar reversul funcției cumulative de distribuție, CCDF⁻¹; mai precis, pentru orice nivel de încredere I, unde I este procent, valoarea lui z cu care vom defini intervalul de încredere este deci CCDF⁻¹(α/2).
Menționăm câteva valori frecvent folosite pentru interval de încredere:
| Procent caracterizând un interval de încredere | Proporție din cazuri considerată normală, centrală, tipică | Proporție din cazuri considerată extremă (suma celor două cozi, α) | CCDF | CDF | Poziție z care partiționează cu aceste arii |
| 90% | 0,9 | 0,1 | 0,05 | 0,95 | 1,64 |
| 95% | 0,95 | 0,05 | 0,025 | 0,975 | 1,96 |
| 99% | 0,99 | 0,01 | 0,005 | 0,995 | 2,57 |
Așa cum spuneam mai sus, pentru interval de încredere 95%, cazurile centrale se vor afla la maximum 1,96 erori standard de centrul distribuției. În cazul mediei, nu știam centrul distribuției (media populației, μ), dar aproximam cu media eșantionului, X̄; și nu cunoșteam eroarea standard a populației σ, dar o aproximam cu eroarea standard desprinsă din eșantion \(s=\frac{\sum{d_{x_i}}}{n-1}\).
Nu ar trebui să nu fie necesară învățarea acestor numere.
- La examenele scrise, ar trebui să aveți în enunț o propoziție de forma “se cunoaște că z0,025 = 1,96″, care precizează, cu această notație aparte, CCDF⁻¹(α/2). În astfel de cazuri, este de așteptat să motivați folosirea acelei valori a lui z, afirmând că “pentru un eșantion de efectiv mare și un interval de încredere 95%, unui nivel de încredere I, exprimat ca procent, îi corespunde nivelul de semnificație α = 1 – (I/100), și respectiv coeficientul corespunzător acestui nivel de încredere egal cu zα/2“.
- De exemplu, pentru intervale de încredere 90% care necesită distribuția normală, problema ar putea să se încheie cu “se cunoaște că z0,05 = 1,64″, dar va fi necesar să explicați: “Pentru un interval de încredere 90%, vom avea un nivel de încredere de α = 1 – (I/100) = 1 – (90/100) = 0,1. Pentru un interval de încredere pentru acest parametru, care urmează distribuția normală, vom folosi coeficientul corespunzător acestui nivel de încredere egal cu zα/2 = z0,1/2 = z0,05 = 1,64″.
- La examenele practice, puteți obține aceeași valoare 1,96 în Excel cu NORM.INV(0.975, 0, 1), adică veți trimite ca argument pe 1-(α/2), funcția NORM.INV fiind de fapt CDF⁻¹(1 – (α/2)).
- Materialele anglofone notează cu zᵢ inversul lui CDF. Acolo unde românii (germanii, rușii) scriu “z0,05 = 1,64″, anglofonii scriu “z0.95 = 1.64″ (adică 1-α/2 în loc de α/2). La ei, numărul indice de la z ete identic cu cel argument pentru NORM.INV(). Atenție la Wikipedia și LLMuri.
Distribuția t
Distribuția normală caracterizează mediile de eșantion selectat aleator. Folosim frecvent această proprietate a mediilor de eșantion, deși distribuția normală care ar trebui aplicată depinde de parametri populaționali necunoscuți. Mai precis, dispersia în mulțimea mediilor de eșantion este \( \frac{\sigma^2}{n} \), dar noi o aproximăm cu \( \frac{s^2}{n} \). Pentru eșantioane mici (n<30), deosebirea între s și σ devine notabilă. Mediile de eșantion pentru eșantioane mici și σ necunoscut, aproximat cu s, se încadrează într-o distribuție numită t, cu formă ușor diferită în funcție de mărimea eșantionului.
Puteți ajusta aria regiunii centrale în imaginea de mai jos, pentru a observa valorile critice ce definesc acea regiune în distribuția normală, în distribuția t pentru n=10 și în distribuția t pentru n=5.
Pentru intervale de încredere plecând de la eșantioane mici, veți avea nevoie de valoarea lui t care, împreună cu opusul său -t, delimitează o regiune de valori centrale de proporție I/100 și două cozi de proporție totală α. Pentru un eșantion de efectiv n=10 și un interval de încredere 95%, începem prin a calcula nivelul de semnificație 1 – (I/100), aici 1 – (95/100). Apoi:
- La examene scrise, vi se preciza “se cunoaște t0,025;9 = 2,26″. Din nou,, economiștii români preferă CCDF⁻¹(α/2).
- La examenele practice, puteți obține aceeași valoare 1,96 în Excel cu T.INV(0.975, 9), adică veți trimite ca argumente pe 1-(α/2), funcția T.INV fiind de fapt CDF⁻¹ₜ(1 – (α/2)).
În ambele cazuri, al doilea argument, aici 9, este numărul de grade de libertate. În cazul mediilor de eșantion, numărul de grade de libertate era egal cu n-1, unde n este numărul de unități statistice din eșantion. În cazul regresiei, numărul gradelor de libertate necesare pentru intervale de încredere este egal cu numărul de grade de libertate al sumei pătratelor reziduurilor (vezi mai jos).
Indiferent că veți avea nevoie de valori ale z (de exemplu, z0,025), sau de valori ale lui t (de exemplu, t0,025;9), acestea vor fi coeficientul corespunzător nivelului de încredere.
- Veți înmulți coeficientul corespunzător nivelului de încredere cu abaterea pătratică standard (eroarea standard) a ceea ce ați estimat, pentru a calcula eroarea limită de reprezentativitate.
- Veți aduna și respectiv scădea acea eroare limită de reprezentativitate din estimația punctuală pentru a obține limitele intervalului de încredere.
Grade de libertate
Pentru o variabilă cu n observații independente, spunem fiecare valoare este liberă în raport cu celelalte.
O dată ce am calculat media, adăugăm o constrângere putem modifica n-1 dintre valori liber, dar ultima va trebui ajustată la o anume valoare dacă dorim ca media să rămână neschimbată. Spunem că au mai rămas doar n-1 grade de libertate.
Dacă folosim aceste numere la un model de regresie cu p predictori excluzând termenul liber, nu vom mai putea modifica liber nici măcar n-1 valori, dacă dorim ca β₁, β₂, .. βₚ să rămână aceeași. Mai precis, adăugarea unui predictor, cu excepția termenului liber, adaugă o nouă restricție, și reduce numărul de grade de libertate pentru reziduuri.
Astfel, în convenția în care p descrie numărul de predictori excluzând termenul liber (cea comună în Excel, SPSS, Eviews), vom spune că avem:
- un număr total de grade de libertate (dftotal) egal cu n-1
- un număr de grade de libertate ale reziduurilor (dfresiduals) egal cu n-p-1
- un număr de grade de libertate al regresiei (dfregression) egal cu diferența celor de mai sus (n-1) – (n-p-1) = p.
În unele manuale, sunt numărați predictorii inclusiv termenul liber, cel mai frecvent rezultatul acestei numărători fiind notat k. În acest caz, vom spne că avem:
- un număr total de grade de libertate (dftotal) egal cu n-1
- un număr de grade de libertate ale reziduurilor (dfresiduals) egal cu n-k
- un număr de grade de libertate al regresiei (dfregression) egal cu diferența celor de mai sus (n-1) – (n-k) = k-1.
Rezultatul este același. De exemplu, pentru un model de regresie simplă, avem
- p=1 (un predictor excluzând termenul liber) și
- k=2 (doi predictori, dacă includem și termenul liber).
În ambele cazuri, avem
- un număr total de grade de libertate (dftotal) egal cu n-1
- un număr de grade de libertate ale reziduurilor (dfresiduals) egal cu n-2
- un număr de grade de libertate al regresiei (dfregression) egal cu diferența celor de mai sus 1.
Aceste grade de libertate sunt necesare inclusiv la calcularea intervalelor de încredere.
Există cazuri când va fi preferabil un model de forma Y = β₁X, sau chiar Y = β₁X₁ + β₂X₂ + …etc, fără includerea unui termen liber. În acest caz, avem
- un număr total de grade de libertate (dftotal) egal cu n (efectivul eșantionului)
- un număr de grade de libertate al regresiei (dfregression) egal cu p (numărul predictorilor)
- un număr de grade de libertate ale reziduurilor (dfresiduals) egal cu n-p.
Eroarea standard a regresiei
Revenind la exemplul nostru cu n=8 state europene, să examinăm mai departe acest eșantion regenerat la fiecare 30 de minute:
Pentru un model de regresie liniară simplă \(PIB_{i} = \beta_0 + \beta_1 \times Pop_{i} + \epsilon_{i}\), estimațiile parametrilor sunt:
Cu informațiile din secțiunea precedentă și cu cele din algoritmul discutat în secțiunea precedentă, putem descrie ceea ce se numește tabelul Analysis of variance (ANOVA):
Am adăugat deci o coloană cu așa-zise medii de pătrate, care se obțin din sume de 8 pătrate, prin împărțirea la numere diferite de 8:
- SStotal / dftotal este Var[Y] cu împărțire la n-1, adică varianța (dispersia) lui Y, folosind procedeul necesar când estimam dintr-un eșantion valoarea pentru populația mamă (de fapt, media abaterilor lui Y de la media sa în populația-sursă)
- SSresiduals / dfresiduals este varianța erorilor (uneori varianța reziduurilor), motiv pentru care este abreviată MSE (Mean Square Error), și estimează media pătratelor erorilor în populație, pornind de la reziduuri din eșantion.
- SSregression / dfregression estimează cât, din varianța capturată de model, este în medie atribuibil fiecăruia dintre predictori, motiv pentru care se numește Mean Square due to Regression (abreviat Mean Square Regression sau MSR).
Pentru pașii următori este esențial MSE. Rădăcina sa pătrată, numită eroarea standard a regresiei (eng. standard error of the estimate), estimează abaterea pătratică medie a erorilor.
- În contextele în care parametrul “abaterea pătratică a erorilor” se notează σ, estimatorul său, \( \sqrt {MSE} = \sqrt{ \frac {\sum{\hat{\epsilon_i}^2}}{n-p}} \) se notează σ̂, sau, prin asemănare cu abaterea pătratică medie a variabilei, în cazul eșantioanelor, cu litera latină s.
- În unele aplicații, eroarea standard a regresiei este numită eroare standard a modelului sau eroarea standard a estimării.
- Prin asemănare cu abaterea pătratică a variabilei, care adesea avea indice (de ex, sₓ), eroarea standard a estimării se mai notează σ̂ₑ, sₑ, σ̂ₘ, sₘ, σ̂ε, sε.
Aici
Intervale de încredere pentru modelul de regresie liniar simplu
La modul general, valorile erorilor standard sunt calculate prin metoda matricială descrisă în capitolul dedicat acesteia. Pentru un singur predictor pe lângă termenul liber, formulele se simplifică până la forme memorabile și ușor de calculat. Astfel:
- \(SE(\hat{\beta}_1) \;=\; \hat{\sigma} \frac{1}{\sqrt{Sxx}} \)
- \(SE(\hat{\beta}_0) \;=\; \hat{\sigma} \sqrt{\frac{1}{n} \;+\; \frac{\bar{X}^2}{Sxx}} \)
Aici:
Ambele estimări provin dintr-o distribuție t cu un număr de grade de libertate egal cu dfresiduals (aici 6). Dacă ne propunem să calculăm intervale de încredere 95%, vom converti la nivel de semnificație α, aici 1-(95/100) = 0,05.
- La examenul scris, se va preciza CCDFₜ⁻¹(α/2) cu formula “se cunoaște t0,025;6 = 2,45″, al cărei utilizare va trebui justificată cu “Pentru un interval de încredere 95%, vom avea un nivel de încredere de α = 1 – (I/100) = 1 – (95/100) = 0,05. Pentru un interval de încredere pentru acest parametru, care urmează distribuția t cu dfresidue = 6 grade de libertate, vom folosi coeficientul corespunzător acestui nivel de încredere, egal cu tα/2,dfresidue = t0,05/2;6 = t0,025;6 = 1,94″.
- La examenul practic, vom calcula CDFₜ⁻¹(1 – α/2) cu T.INV(0.975, 6).
Erorile limită de reprezentativitate vor fi produsul erorii standard cu coeficientul de încredere:
Intervalul de încredere 95% va fi obținut prin scădere și adunare de la estimarea punctuală (cea cu un singur număr) a erorii limită:
Veți încheia cu afirmația / afirmațiile:
Interval de încredere pentru valorile previzionate
Există două tipuri de previzionare în privința unităților statistice incomplet cunoscute. Putem previziona media PIBurilor mai multor state cu aceeași populație X₀, sau putem previziona valoarea PIBului unui stat cu acel PIB egal cu X₀. Ca valoare punctuală, ambele sunt rezultatul introducerii lui X₀ în formula modelului Yᵢ = β̂₀ + β̂₁ Xᵢ. (Cum un model la care media reziduurilor este 0, cea mai bună previzionare pentru reziduul valorii propuse este 0.)
Propunem această unitate statistică care nu a făcut parte din eșantion:
Modelul va previziona, atât pentru un stat cu acea populație, cât și pentru media mai multor state cu acea populație, ca valoare punctuală, PIBul acesta:
Eroarea standard a acestor previzionări este
- pentru valoarea medie estimată, \(SE(\hat{Y}_0) = \hat{\sigma}\sqrt{\frac{1}{n} + \frac{(X_0 – \bar{X})^2}{S_{xx}}}\)
- pentru valoare unică nou-observată \(SE(\hat{Y}_{0,\text{pred}}) = \hat{\sigma}\sqrt{1 + \frac{1}{n} + \frac{(X_0 – \bar{X})^2}{S_{xx}}}\)
Aici:
Să presupunem că dorim intervale de încredere 90% pentru cele două estimări. Începem prin a calcula nivelul de semnificație α = 1 – (I/100), aici 0,1. Ulterior, coeficientul de încredere ne parvine pe una din două căi:
- La examenul scris vom primi CCDF⁻¹ₜ(α/2), cu formula “se cunoaște t0,05;6 = 1,94″, al cărei utilizare va trebui justificată cu “Pentru un interval de încredere 90%, vom avea un nivel de încredere de α = 1 – (I/100) = 1 – (90/100) = 0,1. Pentru un interval de încredere pentru acest parametru, care urmează distribuția t cu dfresidue = 6 grade de libertate, vom folosi coeficientul corespunzător acestui nivel de încredere, egal cu tα/2,dfresidue = t0,1/2;6 = t0,05;6 = 1,94″.
- La examenul practic, vom calcula CDFₜ⁻¹(1 – α/2) cu T.INV(0.95, 6).
Eroarea limită de reprezentare este produsul coeficientului corespunzător nivelului de încredere cu eroarea standard. Aici:
Și aici, intervalul de încredere se va obține prin adunarea și scăderea erorii limită de reprezentare din estimarea punctuală:
Recapitulare
- O metodă standardizată de prezentare a datelor din regresia liniară este tabelul ANOVA, care cuprinde
| Sumă de pătrate | Grade de libertate | “Media” pătratelor | |
| Total | SStotal = Syy = Σd² | n-1, dacă modelul include termen liber | MST = SStotal / grade de libertate totale, estimează media pătratelor abaterilor în populație |
| Reziduuri | SSresiduals = Σε̂² | (grade de libertate totale) – (grade de libertate ale regresiei) | MSE = SSresiduals / (grade de libertate ale reziduurilor), estimează media pătratelor erorilor |
| Regresie | SSregression= SStotal – SSresiduals | p, numărul de predictori excluzând termenul liber | MSR = SSregression / (grade de libertate ale regresiei), estimează cât din variabilitatea lui Y este captată de un predictor |
- Intervalul de încredere este un interval definit de datele din eșantion, dar și de un procent denumit nivel de încredere. De exemplu, se va cere interval de încredere 95%, situație în care 9% este nivel de încredere.
- Intervalul de încredere se calculează cu (estimație punctuală – eroare limită de reprezentare) … (estimație punctuală + eroare limită de reprezentare), unde estimația punctuală (valoarea cea mai probabilă) este descrisă în capitolele precedente, atât pentru parametrii β₀, β₁ etc, cât și pentru previzionările Y₀.
- Eroarea limită de reprezentare este produsul a două numere, un coeficient corespunzător nivelului de încredere și o abatere standard.
- Abaterea standard este o măsură a variabilității pentru indicatorul estimat, în acel eșantion. Pentru regresie liniară simplă, abaterile standard sunt:
- pentru pantă, \(SE(\hat{\beta}_1) \;=\; \hat{\sigma} \frac{1}{\sqrt{Sxx}} \)
- pentru termenul liber, \(SE(\hat{\beta}_0) \;=\; \hat{\sigma} \sqrt{\frac{1}{n} \;+\; \frac{\bar{X}^2}{Sxx}} \)
- pentru valoarea Yₒ a variabilei previzionate pentru o unitate statistică nouă, pe baza modelului și a unei valori a predictorului de X₀, \(SE(\hat{Y}_{0,\text{pred}}) = \hat{\sigma}\sqrt{1 + \frac{1}{n} + \frac{(X_0 – \bar{X})^2}{S_{xx}}}\)
- pentru media tuturor valorilor variabilei previzionate pe baza modelului, dată fiind o valoare a predictorului X₀, \(SE(\hat{Y}_0) = \hat{\sigma}\sqrt{\frac{1}{n} + \frac{(X_0 – \bar{X})^2}{S_{xx}}}\).
- Pentru abaterea standard a celor patru indicatori de mai sus în regresie liniară multiplă, se folosește metoda de calcul matricial.
- Coeficientul corespunzător intervalului de încredere este întotdeauna CCDF()⁻¹, adică poziția pe axa X care delimitează către +∞ o “coadă” de dimensiunea indicată de intervalul de încredere.
- Pentru intervalele de regresie relevante în acest capitol, vom avea întotdeauna două cozi de arie egală.
- Aria combinată a celor două cozi este numită nivel de semnificație α, care se calculează cu 1 – (i/100), unde i este procentul de încredere al intervalului.
- Coeficientul corespunzător procentului de încredere este deci CCDF⁻¹(α/2).
- De regulă, funcția care descrie distribuția estimațiilor din acest capitol este distribuția t, o distribuție similară ca formă distribuției normale (simetrică, extinsă la infinit etc), însă din ce mai ce mai aplatizată în funcție numărul de grade de libertate al reziduurilor.
- Pentru a indica dependența de numărul de grade de libertate (gl), CCDF⁻¹(α/2) se scrie tα/2,gl. De exemplu, pentru un interval de încredere 95% în cazul când reziduurile au 6 grade de libertate, vom scrie coeficientul corespunzător procentului de încredere ca fiind t0,025;6. Valoarea sa este tabelată (ar trebui precizată în textul problemei) sau se calculează în Excel cu T.INV(0.975, 6).
- În cazurile când numărul de grade este mai mare de 30, distribuția t devine aproximativ egală cu distribuția normală.
- În cazul utilizării distribuției normale, vom scrie CCDF⁻¹(α/2) ca zα/2. De exemplu, pentru un interval de încredere 95% în cazul când reziduurile au 100 de grade de libertate, vom scrie coeficientul corespunzător nivelului de încredere ca fiind z0,025. Valoarea sa este tabelată (ar trebui precizată în textul problemei) sau se calculează în Excel cu NORM.INV(0.975, 0, 1).
Probleme propuse
1. Am construit un model de regresie liniară, previzionând PIBul, plecând de la un eșantion de țări. Se cunosc:
Completați tabelul ANOVA. Calculați coeficientul de determinare și interpretați-l. Calculați statistica F=MSR/MSE.
Răspuns:
2. Am construit un model de regresie liniară, previzionând PIBul, plecând de la un eșantion de țări. Se cunosc:
Completați tabelul ANOVA. Calculați coeficientul de determinare și interpretați-l. Calculați statistica F=MSR/MSE.
Răspuns
3. Am construit un model de regresie liniară simplă, previzionând PIBul pe baza Populației, plecând de la un eșantion de țări. Se cunosc:
Să se estimeze parametrii modelului de regresie liniară simplă PIB = β₀ + β₁·Pop + ε ca valori punctuale și ca intervale de încredere 95%. Se cunoaște că:
Răspuns
Din eșantion sunt necesare valori pentru: β̂₁ = Sxy/Sxx; β̂₀ = Ȳ – X̄β̂ ₁; SE[β̂₁] = σ̂ / √Sxx; SE[β̂₀] = σ̂ √[(1/n) + (X̄²/Sxx)]. Cele care nu sunt deja în enunț sunt Sxy, Sxx, Syy și σ̂.
Estimațiile punctuale pentru cei doi parametri sunt:
Pentru abaterea standard a estimației este necesară completarea întregului tabel ANOVA:
Un ultim ingredient este coeficientul corespunzător nivelului de încredere, aici în enunțul problemei. Este necesar să justificați utilizarea acelui număr astfel:
4. Un model de regresie liniară simplă PIB = β₀ + β₁·Pop + ε are următoarele caracteristici:
Să se estimeze ca valoare punctuală și ca interval de încredere 90% valoarea previzionată a PIBului pentru o altă țară, cu proprietățile:
Se cunoaște că:
Răspuns
Estimația punctuală este Y₀ = β̂ ₀ + β̂ ₁ X₀, toate valorile fiind cunoscute.
Pentru interval și pentru eroarea limită de reprezentativitate este necesară abaterea pătratică a lui Yₒ, SE[Yₒ] = σ̂ · √[1 + (1/n) + (X₀-X̄)/Sxx], din care nu cunoaștem X̄, σ̂ și Sxx. X̄ se poate calcula din proprietatea curbei de regresie de a trece prin punctul de coordonate (X̄,Ȳ).
Vom completa tabelul ANOVA, unde se regăsesc MSE = σ̂ ² și SSregression = β̂ ₁² × Sxx.
Extragem indicatorii necesari:
Pentru a justifica utilizarea coeficientului corespunzător nivelului de încredere, este utilă o explicație de forma:
Putem trece la calcularea intervalului de încredere:
Rezultatul ar fi fost ușor diferit dacă se cerea intervalul de încredere pentru media PIBurilor (media valorilor lui Yₒ) pentru o populație dată: