
Excel are peste 40 de ani de existență și este cel mai comun mod de a manipula datele tabelare. În ultimii 20 de ani a fost îmbunătățit din punct de vedere al capabilităților statistice, până la un nivel ce îl face apt pentru majoritatea sarcinilor pe care le veți primi în cursul celor 3 ani de licență. Conectarea sa la date externe a fost extrem de mult îmbunătățită în ultimul deceniu prin transferul de funcții de la alt produs Microsoft mai capabil în ceea ce privește prelucrarea primară și reprezentarea grafică, numit PowerBI.
Din cauza modificărilor repetate, cursul de Statistică de anul 1 prezintă mai multe moduri de a rezolva aceeași problemă, cele mai primitive fiind mai bine cunoscute de potențialii voștri colaboratori, iar cele mai recente fiind de regulă mai eficiente. În plus, nu puteți obliga partenerii voștri să cumpere cel mai recent Excel, când versiunile de la începutul secolului încă funcționează și rezolvă majoritatea problemelor unui utilizator. Dacă un fișierul folosește funcții extrem de recent introduse, majoritatea calculatoarelor lumii nu vor fi capabile să îl folosească. Este ideal să vă plasați așteptările la Excel 97, care continuă să ruleze și în Windows 10. Un alt punct de referință este Excel 2010, la care Microsoft a urmat multe din cererile utilizatorilor dezamăgiți de versiunea precedentă, recuperând astfel parte din prestigiul pierdut cu Excel 2007.
În procesarea în Excel, este ideal să folosiți la maximum formule, și să păstrați metodele point-and-click pentru cazurile rare în care formula nu funcționează, pentru ca eventualii colaboratori sau critici să aibă o listă clară a procedurilor pe care le-ați folosit. Folosirea lui point-and-click este rețeta pentru erori imperceptibile, cu efect dureros pe termen lung. De exemplu, traderul supranumit London Whale a pierdut 6 miliarde de dolari din banii clienților JP Morgan Chase fiindcă își făcea calculele cu copy-paste. În 2010-2012, guvernele american și britanic au redus ajutoarele sociale, iar Uniunea European a limitat împrumuturile către PIGS (Portugalia, Italia, Grecia, Spania), deoarece se credea că îndatorarea statelor peste un anume prag are efecte severe asupra creșterii economice. Această teorie s-a dovedit nefondată, articolul și cartea în care ideea a fost popularizată fiind bazat pe un fișier Excel prelucrat manual, cu point-and-click, care omitea cifre importante.
În această secțiune, vom discuta cu precădere procesarea datelor alfanumerice, și derivarea din acestea a variabilelor cantitative.
Cuprins
Problema separatorului zecimal
În România, Germania, Rusia, Franța, Italia, Spania, unitățile sunt separate de zecimi cu virgulă, dar în SUA, Japonia, India, în același scop se folosește punctul. Este ideal să folosiți separatorul zecimal corespunzător limbii în care e scrisă prezentarea. O problemă similară, dar mai ușor de rezolvat, este cea a separatorului dintre mii și zeci de mii, culturile cu punct zecimal preferând virgula, iar cele cu virgulă zecimal, precum România, preferând punctul sau spațiul.
Atunci când producem date, separatorul poate fi controlat de noi. Pe de o parte, există setarea generală din Control Panel al Windows, care este sugerată și tuturor aplicațiilor de pe acel sistem.
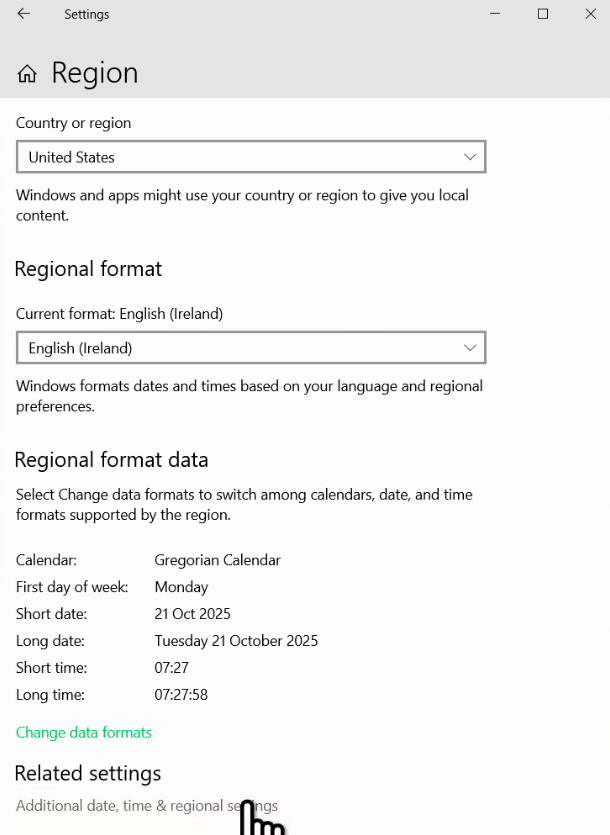
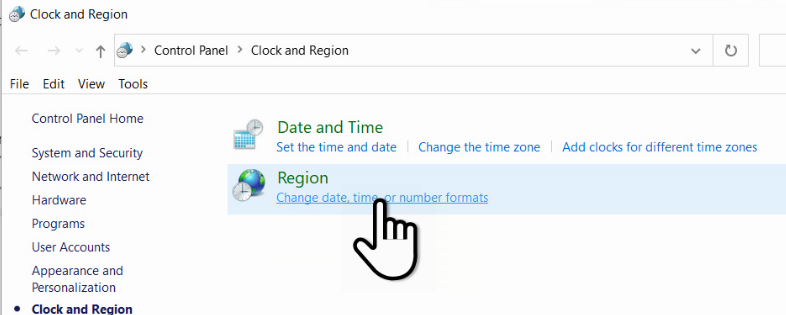
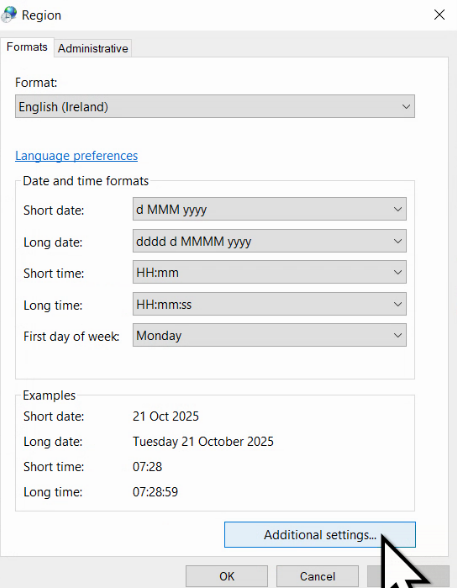
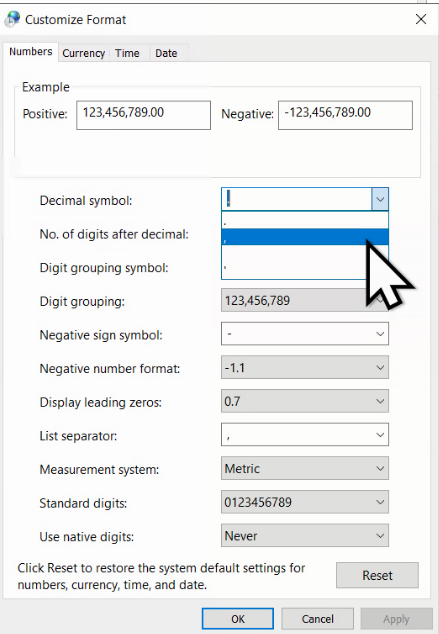
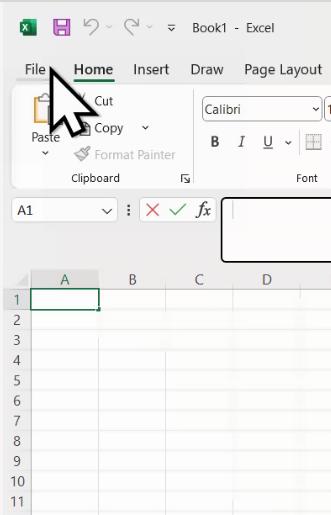
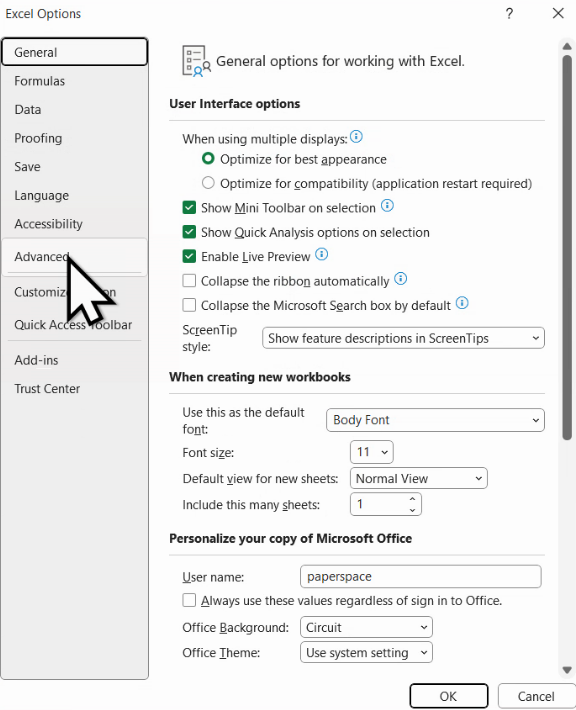
În plus, în Microsoft Excel, putem ajusta independent acești separatori, în File – Options – Advanced, demarcând Use system separator.

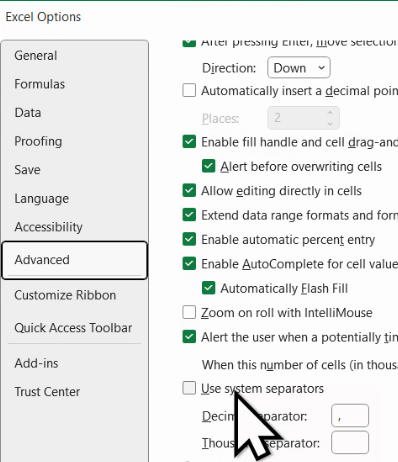
Din nefericire, în mediile organizaționale, unul sau ambele mecanisme sunt blocate de administratorii de sistem, iar computerul va insista să folosească separatorul greșit. Chiar dacă Excel menține o separație clară între valoare numerică și modul cum este prezentată pe ecran, conflictele între separatori sunt o problemă majoră atunci când importăm date din altă cultură. De exemplu, poate fi o provocare să importăm, într-un Excel setat cu separatori potriviți pentru România, date din Wikipedia engleză.
Tabelul cu toate localităile urban ale României se află la https://en.wikipedia.org/wiki/List_of_cities_and_towns_in_Romania. L-am selectat, am dat Copy, am revenit în Excel la celula A1, unde am dat Paste.
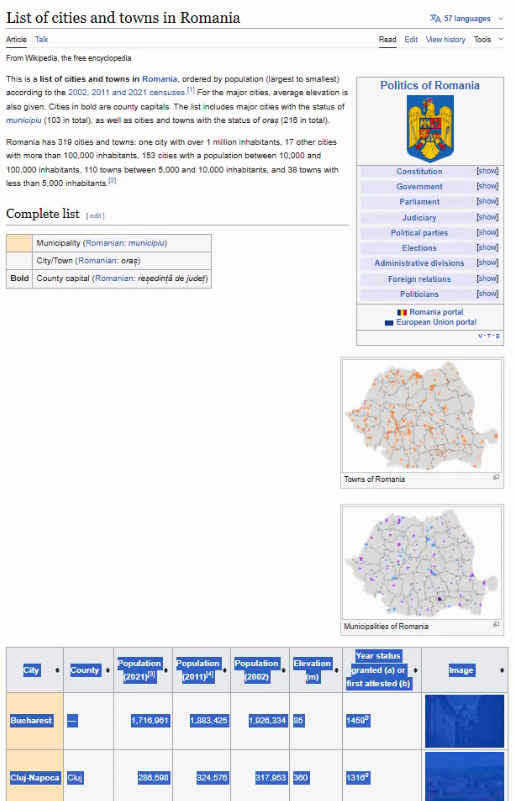
Detur cosmetic
În versiunile recente, Excel va transforma datele lipite din browser în moduri surprinzător de elegante, dacă veți folosi Paste Matching Destination Format, din dropdownul de sub Paste. Chiar și cu această opțiune modernă, rezultatul lipirii poate fi unul nepractic, atunci când persistă imaginile sau hiperlinkurile (detalii mai jos). Această secțiune descrie tratamentul unor date lipite cu Paste simplu, în ideea că unele dintre aceste corecții vor fi necesare chiar și la folosirea lui Paste Matching Destination Format, opțiune al cărei eficiență diferă de la tabel la tabel și de la computer la computer.
Cu clic pe pătratul gri dintre eticheta de linie 1 și eticheta de coloană A selectăm întreaga foaie de calcul, și
- cu 1 sau 2 clicuri pe butonul
Bold,UnderlineșiItalic, dezactivăm aceste opțiuni la nivelul întregii foi - cu selecții din dropdownurile corespunzătoare, setăm același font, de exemplu
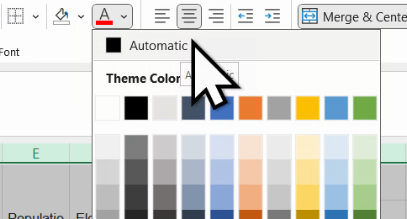
Arial,10 pt - to din dropdownuri, dar de sub butoane grafice, eliminăm diversele borderuri (alege
No border), culori de fundal (No fill) și culori pentru font (Automatic).

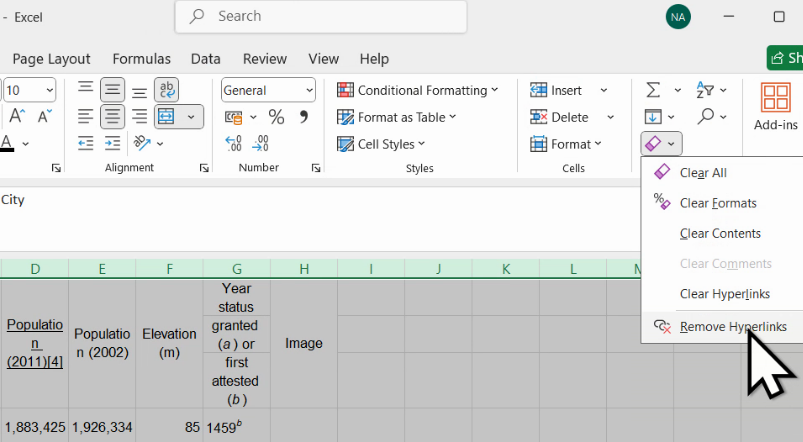
Persistența hiperlinkurilor va face cvasimposibil clicul în celulele cu date, fiecare clic ducând la deschiderea unei noi pagini în browser. Pentru a elimina hiperlinkurile, selectăm întreaga foaie cu clic pe dreptunghiul gri dintre eticheta de linie 1 și eticheta de coloană A și alegem lui Remove Hyperlinks, din dropdownul de sub Clear.
O parte mai mare sau mai mică dintre modificările de mai sus se pot obține, în versiuni mai noi, selectând întreaga foaie, și dând clic pe Clear Formats de sub Clear.
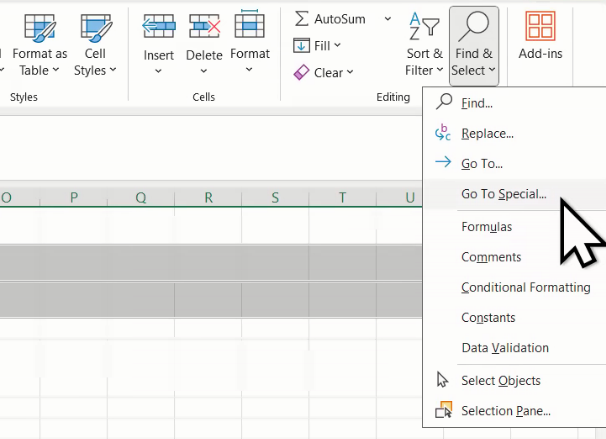
Un alt element cosmetic tratabil este persistența imaginilor fiecărui oraș, care oate mări consumul de memorie cu sute de megabytes și încărca ecranul, fără a contribui la analiză. Pentru a elimina imaginile, vom folosi Go To Special de sub Find and Replace:
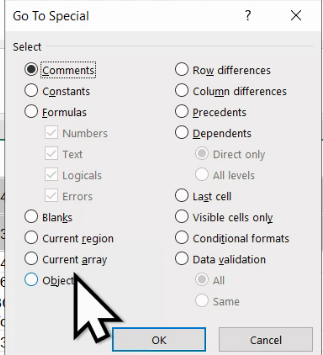
Din fereastra Go to Special, putem selecta Objects, un grup de date ce include imaginile:

Uneori imaginile vor fi fost vizibile, însă în alte configurații, veți constata că toate imaginile din tabelul hipertext au ajuns în fișierul vostru Excel în formă ascunsă, în spatele celulelor cu date:
O dată selectate imaginile, apăsați o singură data tasta Delete, pentru a le șterge.
O altă problemă a tabelelor hipertext este practica comună de a întinde o celulă pe mai multe rânduri sau coloane, ceea ce va face dificilă extinderea rapidă a formulelor necesare statisticii. În Excel, operația de unire a mai multor celule într-una singură, de-a lungul mai multor rânduri sau coloane, se numește Merge. De exemplu, în imaginile de până acum, capul de tabel se întinde pe rândurile 1-3. Mai precis, eticheta de linie “City” se află în reuniunea celulelor A1:A3, eticheta “County” – în reuniunea celulelor B1:B3. Pentru dezbinarea acestor celule unite, selectați aceste trei rânduri și alegeți Merge and Center.
Un singur clic pe acest buton va inactiva opțiunea Merge în celulele selectate. Pentru a elimina rândurile inutile 2 și 3, selectați-le, dați clic dreapta pe etichetele lor de rând, și alegeți Delete:
În funcție de versiunile de browser și Excel, și de setările lor, este posibil ca aceste trei rânduri să nu fi fost singurele îmbinate. În imaginea de mai jos, și celulele A26:A31, B26:B31, etc, dar și A37:A42, B37:B42 etc, sunt unite:
Problema poate fi rezolvată manual, ca mai sus, la fiecare grup de linii. Există însă și o manieră mai eficientă de a rezolva problema tuturor celulelor unite: selectați toată foaia de calcul, și dați clic o singură dată pe Merge and center, astfel dezactivând toate îmbinările:
În acest exemplu, foaia de calcul va conține multe linii fără nume de orașe, cum sunt, în imaginea de mai sus, liniile 36, 37 etc. Pentru a le elimina, este posibilă abordarea manuală de mai sus, sau una globală, care începe cu marcarea liniilor inutile. Dacă suntem în situația din acest exemplu, iar liniile inutile se disting prin lipsa unui nume de localitate în coloana A, începem prin a selecta coloana A:
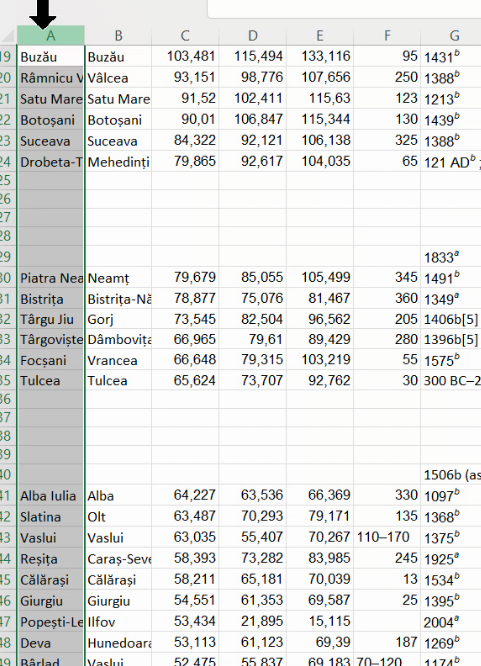
Alegem din nou, de sub Find and Replace, opțiunea Go to Special, însă de data asta vom selecta Blanks:
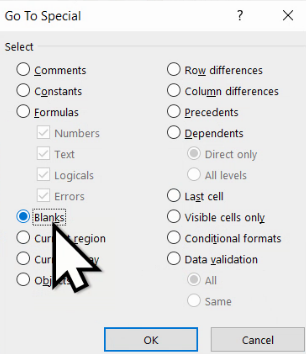
Excel va selecta celulele goale (blank), dar numai din regiunea deja selectată:
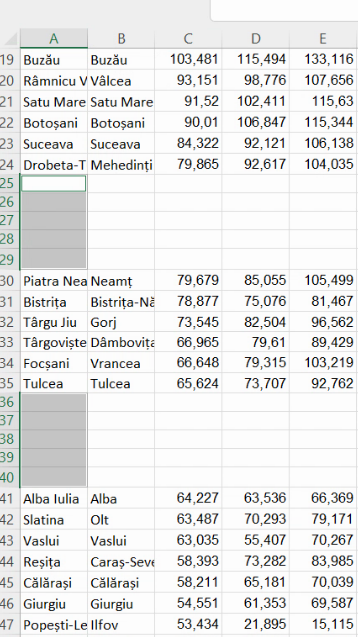
Având această selecție de celule relevante, putem să ștergem simultan toate rândurile în care acestea se află, alegând din meniul de sub Delete, opțiunea Delete Rows:

Ar putea fi necesară reaplicarea corecțiilor cosmetice (font face, font size etc), dar, prin eliminarea linkurilor, imaginilor, celulelor îmbinate și liniilor / coloanelor irelevante, aveți un tabel pregătit pentru prelucrare primară cu formule:

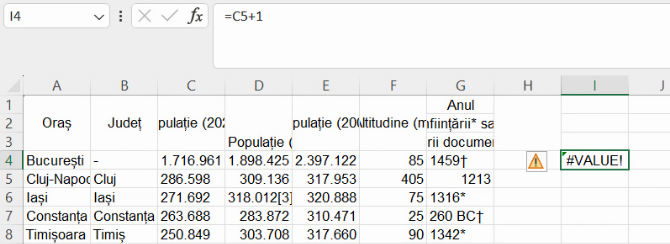
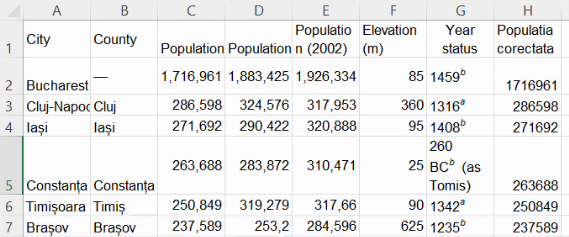
Scenariul în care numerele au fost importate ca numere, dar greșit
Această problemă apare când separatorul folosit de datele sursă semnifică celălalt separator pentru Excel. Pentru imagini, am setat Excel să considere virgula separator într unități și zecimi, dar am importat dintr-un document englez în care virgula semnifică separație între sute și mii.
Acest scenariu se recunoaște prin faptul că Excel afișează importurile ca numere, aliniate la dreapta, și uneori lipsesc cifre finale. În imaginea de mai jos, populația Craiovei are 5 cifre, semn că ceea ce era în tabelul Wikipedia “234,140” a devenit în Excel numărul 234 urmat de câteva cifre zecimale. Cea din urmă, a miimilor, fiind zero, nu mai este afișată de Excel.
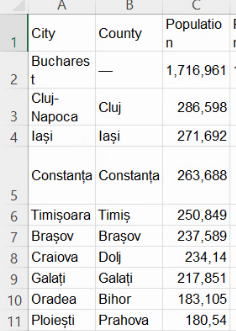
În acest caz, profitând de faptul că nu există localități urban cu sub 1000 de locuitori, vom putea rezolva în mare parte problema, înmulțind numerele din coloana C cu 1000:
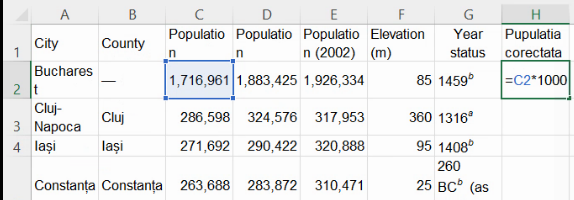
Ignorând eroarea de la București pe moment, extindem formula din H2 până la baza tabelului.
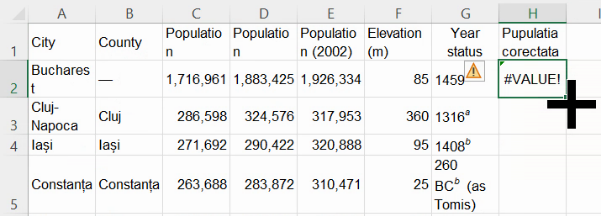
Frecvent, când cursorul are acea formă, este suficient un dublu-clic pentru a extinde formula până la baza tabelului:
Pentru populația Bucureștiului, putem scrie formula mai potrivită SUBSTITUTE(C2, ",", ""), formulă ce va înlocui în C2 fiecare virgulă cu un șir vid.
Funcția
SUBSTITUTE()e folosită cu trei argumente, un text-sursă, un șir de caractere ce va fi înlocuit, și un alt șir cu care se va face înlocuirea. De exemplu,SUBSTITUTE("mama", "m", "t")va returna “tata”. Fiecare din cele trei argumente alfanumerice poate fi scris explicit sau poate fi calculat cu date din restul foii de calcul.
Dacă folosiți un Excel ce folosește virgula pentru numere, așa cum este cel setat pentru acest exemplu, nu veți putea folosi virgula pentru separarea argumentelor. În aceste cazuri, va trebui să separați argumentele lui
SUBSTITUTE()cu punct și virgulă, ca înSUBSTITUTE("mama"; "m"; "t").

Problema nu este complet rezolvată, deoarece SUBSTITUTE() returnează tot date alfanumerice. Un prim indiciu că valoarea din H2 nu este număr alinierea la stânga a conținutului celulei. O garanție ar fi imposibilitatea operațiilor matematice, adică situația când H2+1, 2*H2, etc ar returna erori. În versiunile moderne, Excel va converti automat șirul alfanumeric în număr, și va efectua aceste calcule, dar versiunile vechi de Excel nu vor efectua conversia. Pentru asigura compatibilitatea, vom trimite rezultatul lui SUBSTITUTE() funcției VALUE(), cea mai veche și versatilă funcție de conversie din alfanumeric în numeric:
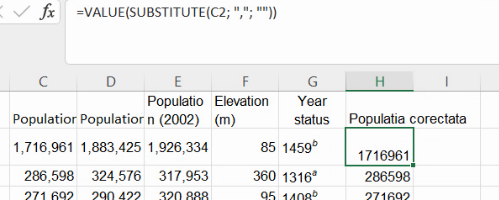
Funcția
VALUE()primește un argument și returnează un număr cu valuarea argumentului. Rolul principal al luiVALUE()este conversia la numeric din alte tipuri. Însă atâtVALUE(1), cu argument numeric, cât șiVALUE("1"), cu argument alfanumeric, vor returna numărul 1. Din păcate,VALUE()operează în limitele setărilor locale. Un Excel setat să folosească, pe model românesc, virgula ca separator zecimal și spațiul ca separator al miilor, nu va ști să transforme în număr șirul alfanumeric “1.1”.
O dată cu trecerea descrierii populației Bucureștiului prin VALUE(), vom observa alinierea la dreapta a conținutului celulei H2, ceea ne sugerează trecerea la format numeric. Testul cel mai bun este o operație matematică, precum scrierea în I2 a formulei =H2+1, care ar trebui să nu producă erori în nici o versiune Excel.
Putem verifica noua coloană, folosind Status Bar Aggregates de pe bara inferioară a Excel. Selectați coloana H. Cu clic dreapta pe bara inferioară, activați statisticile Count și Numerical Count

În acest exemplu, în coloana H avem 320 de celule cu conținut, numărate de Count. Tot în coloana H, avem 319 celule cu numere, conform Numerical Count:

Deci avem o singură celulă care nu a devenit număr, eticheta de coloană. Cu acest fișier, putem trece la analiza statistică a acestei coloane de numere.
Acest fișier este suboptim, deoarece formula din H2 diferă de cea din restul coloanei H, ceea ce face dificilă parcurgerea setului de formule în caz că dorim să confirmăm corectitudinea calculelor. În secțiunea următoare vom discuta o metodă de unificare a formulelor de-a lungul coloanei H.
Scenariul în care numerele sunt importate ca variabile alfanumerice
Acest scenariu are loc atunci când separatorul folosit de datele-sursă nu are sens în Excel. Pentru imaginile de mai jos, am setat Excel să folosească virgula ca separator zecimal și spațiul ca separator între sute și mii. Importul unui document în care punctul separă ceva (aici, sutele de mii) nu are sens pentru Excel, așa că vom avea ceea ce trebuia să fie număr aliniat la stânga și fără capacitatea de a participa la operații matematice.
Am importat cu copy-paste tabelul cu localitățile urbane de la https://ro.wikipedia.org/wiki/Lista_ora%C8%99elor_din_Rom%C3%A2nia. Am aplicat modificările cosmetice descrise în secțiunea precedentă, obținând în coloana C date aparent numerice, dar care totuși nu funcționează ca numere în operații aritmetice:
Pentru a exemplifica o altă abordare, vom ignora opțiunea de a calcula în H2 ca mai sus VALUE(SUBSTITUTE(C2; "."; "")), care ar elimina toate punctele și ar returna o valoare numerică. Vom exersa cu acestă ocazie câteva funcții de procesare a variabilelor alfanumerice, FIND(), LEN(), LEFT() și RIGHT(), precum și concatenarea.
Astfel, putem scoate punctul din populația Clujului, “286.598”, prin reunirea fragmentului dinainte de punct (“286”) cu cel de după punct (“598”). Să începem prin a calcula cele două componente.
Lungimea primului fragment va varia de la 3 cifre la Cluj, până la o cifră la un oraș cu mai puțin de 10 mii de locuitori, însă lungimea fragmentului va fi determinată mereu de poziția punctului. Dacă punctul este al patrulea caracter, fragmentul care îl precede are trei caractere; dacă punctul este al doilea, ca în “1.356”, fragmentul ce îl precede are doar un un caracter. Ca regulă generală, lungimea fragmentului este (poziția punctului) minus 1. Poziția primului punct se calculează cu FIND(), o funcție cu două argumente, ce caut și unde caut.

În forma de bază, funcția FIND() primește două argumente, un șir alfanumeric pe care îl va căuta și un șir alfanumeric în care va căuta. Dacă șirul pe care îl caută se găsește în al doilea argument, va returna poziția primului caracter din șirul căutat. De exemplu,
FIND("re", "Ana are mere")va returna 6, poziția primului “re”.Al treilea parametru, opțional, mută începutul căutării la poziția indicată de acesta. De exemplu,
FIND("re", "Ana are mere", 8)va muta începutul căutării la litera “m”, ceea ce va duce la returnarea valorii 10.Funcția
SEARCH()introdusă în 2016 face tot ce faceFIND()și mai mult.
Într-adevăr, la populația Bucureștiului, primul punct este în poziția a doua:

Putem extinde formula până la baza tabelului:
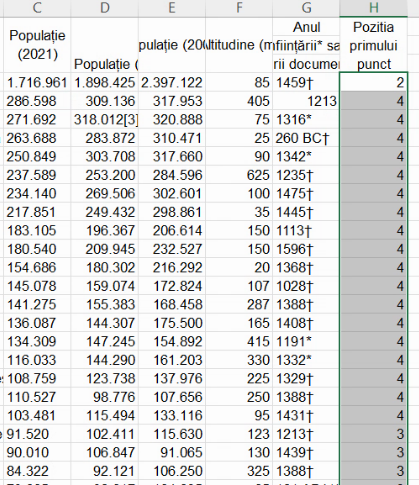
Fragmentul ce precede primul punct are, în cazul Bucureștiului, un caracter, terminându-se imediat în fața poziției punctului, în acest caz 1. Pentru Cluj Napoca, populație 286598, fragmentul din fața punctului (“286”) are trei caractere, iar poziția punctului este calculată în celula H3 ca fiind 4. Pentru Satu Mare, populație 91520, fragmentul din fața punctului are două caractere (“91”), iar poziția punctului este calculată în H21 ca fiind 3. Ca regulă generală, pentru a extrage șirul din fața primului punct, trebuie să păstrăm, din stânga valorilor alfanumerice din coloana C, doar nu număr de caractere egal cu poziția primului punct minus 1.
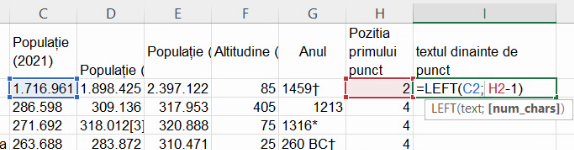
Putem acum extrage fragmentul ce precede punctul cu funcția LEFT(), care primește două argumente, textul-sursă și lungimea fragmentului dorit (aici, poziția primului punct calculată în coloana H minus 1).
Funcția
LEFT()primește două argumente, un șir alfanumeric din care să extragă și un număr de caractere să care să le extragă de la stânga șirului-sursă. De exemplu,LEFT("statistica", 3)returnează “sta“.Funcțiile
LEFT()șiFIND()diferă în tratamentul valorilor absurde. FuncțiaLEFT()nu se va plânge dacă argumentul numeric este exagerat de mare; de exemplu,LEFT("statistica", 99)nu poate returna 99 de caractere, însă va returna, fără reclamații, cele 10 caractere disponibile (“statistica“). În schimb,FIND("a", "statistica", 99)va returna eroare, neputând începe căutarea din poziția 99.
Într-adevăr, textul din fața primului punct este, pentru București, “1”. Extindem și această formulă până la baza tabelului:
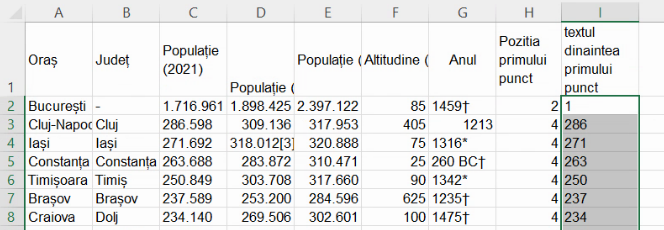
Extragerea textului de după punct va fi ceva mai facilă, pentru că la toate orașele, după ultimul punct se află tot 3 caractere. Echivalentul lui LEFT() este RIGHT():
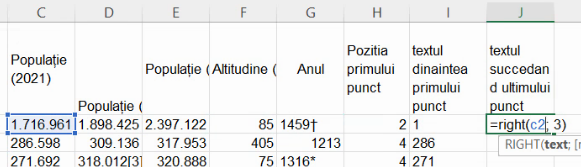
Funcția
RIGHT()primește două argumente, un șir alfanumeric din care să extragă și un număr de caractere să care să le extragă de la dreapta șirului-sursă. De exemplu,RIGHT("statistica", 3)returnează “ica”.
Extindem formula în coloana J:
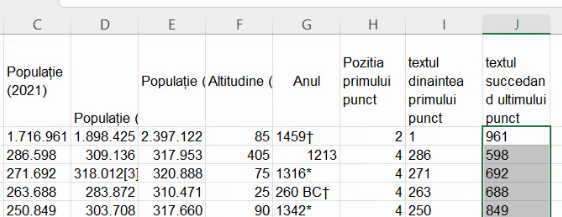
Astfel, în majoritatea cazurilor, pentru a construi numărul ce descrie populația, fără acel punct, vom folosi șirul alfanumeric produc prin lipirea (concatenarea) șirului de cifre din coloana I cu șirul de trei cifre corespunzător din coloana J. În Excel, concatenarea se poate obține cu &.
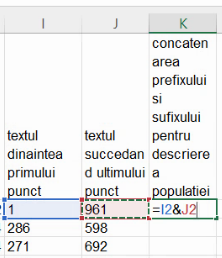
La extinderea formulei de concatenare remarcăm cazul particular al Bucureștiului, la care mai trebuie incluse trei caractere, în afară de cele din fața primului punct și cele din urma ultimului punct:
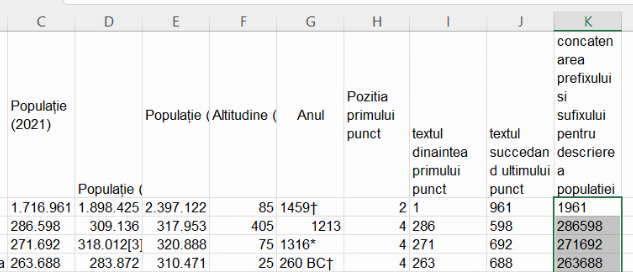
Am putea să repetăm formula din secțiunea trecută, adică SUBSTITUTE(C2, ".", "") doar pentru celula K2. Dar folosirea unei formule diferite în unele părți ale unei coloane de table ne expune aceluiași risc ca operațiile de clic sau drag. Dacă nu putem avea încredere că celula A2 este reprezentativă pentru toate valorile din A sau că formula din K2 nu este aceeași cu restul formulelor din coloana K, orice utilizare a foii de calcul va necesita verificare formulelor din fiecare celulă, în loc de a fi complet informați de linia 2. Aici, vorbim de citirea formulelor din coloanele H, I, J, K, ceea ce implică, în varianta uniformizată, inspecția a patru celule (H2, I2, J2, K2), iar în varianta neuniformizată, a peste o mie de celule (de la H2 la K318).
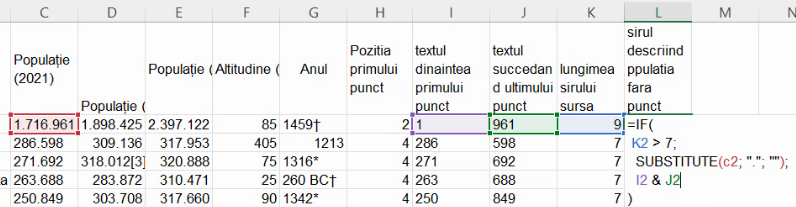
Pentru a folosi o singură formulă în coloana ce reconstruiește numărul din C2 fără puncte, va trebui să folosim și SUBSTITUTE(C2, ".", ""), și I2 & J2, în fiecare dintre celulele acelei coloane. Alegerea este clară: dacă și numai dacă șirul-sursă din celula 2 are cel mult 7 caractere putem folosi concatenarea. Vom folosi pentru lungimea șirului din coloana C funcția LEN(). Reutilizăm coloana K pentru acest calcul:
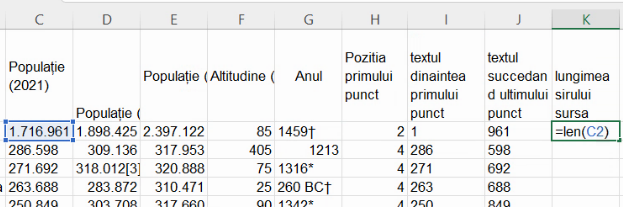
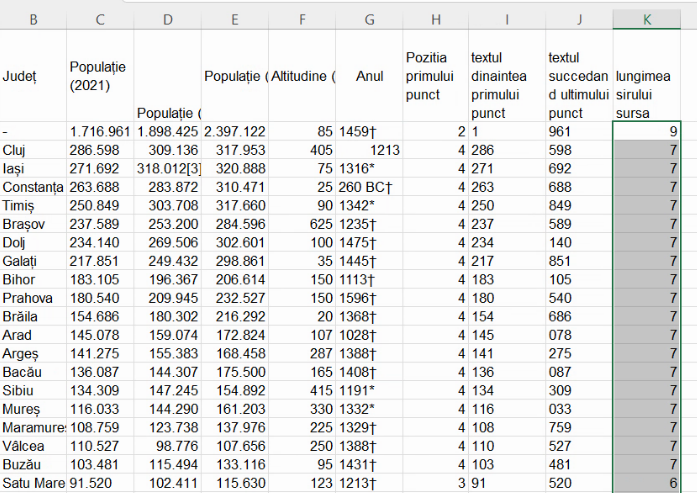
Extindem formula din K2 la întreaga coloană:
Pentru a verifica dacă șirul de cifre și puncte din coloana C este mai lung de 7 caractere, vom folosi funcția IF():
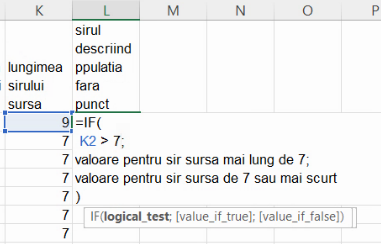
Puteți “rupe” o formulă Excel în mai multe rânduri cu Alt+Enter. Nici funcția IF(), nici altele nu necesită scrierea pe mai multe rânduri sau cu aliniat, aceste pțiui fiind facultative, și preferate pentru lizibilitate.
Funcția
IF()necesită trei parametri, un test logic, o valoare pe care o va returna dacă testul este adevărat și o valoare pe care o va returna dacă testul este fals. De exemplu,IF(2+2 <> 4; "Orwell"; "Huxley")va evalua testul ca fiind fals, și va returna “Huxley“. Operatorul<>(mai mic, urmat de mai mare) testează inegalitatea.
Înlocuim cele două “valori” din imaginea de mai sus cu ceea ce am propus pentru fiecare din ele:
Extindem formula din L2 pe întreaga coloană L:
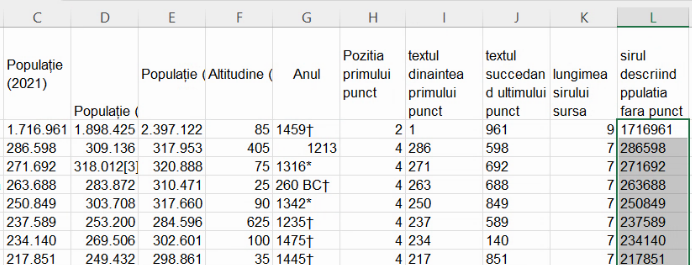
Alinierea rezultatelor la stânga ne reamintește că atât SUBSTITUTE(), cât și concatenarea, returnează valori alfanumerice. Putem confirma caracterul alfanumeric prin folosirea lui Quick Stats, care afișează “Count: 1”, dar nu și Numerical Count. (Chiar dacă o opțiune este activată în Quick Stats, ea nu va fi afișată dacă valoarea ei nu poate fi calculată.)
Cu toate acestea, putem folosi valoarea din L2 în calcule numerice:
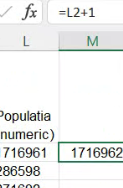
Motivul pentru care Excel poate calcula aici L2+1, dar C5+1 returnase eroare mai sus, este că Excel poate converti șirul alfanumeric din L2 (“1716962”) la un număr, dar nu poate converti șirul alfanumeric din C5 (“1.716.962”) la număr în contextul în care Excel a fost setat să folosească numai virgula și spațiul ca separatori. Deci Excel va converti, atunci când este necesar și posibil, un șir alfanumeric la un număr.
Și operația inversă, de transformare a unui număr într-un șir alfanumeric, poate fi efectuată de Excel când este necesar, de exemplu când numărul este trimis unei concatenări. Concatenarea cu & va returna întotdeauna o valoare alfanumerică, motiv pentru care un truc clasic pentru convertirea unei valori numerice în una alfanumerică este concatenarea cu șirul vid. De exemplu, în altă foaie de calcul, putem converti valoarea probabil numerică (aliniată la stânga) din A1, astfel:
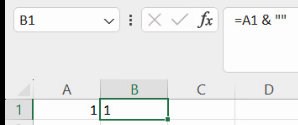
Rezultatul este aliniat la dreapta, sugerând stocarea valorii din B1 ca șir de caractere.
Ambele conversii de mai sus, de la alfanumeric la numeric și invers, sunt efectuate de Excel fără a i se solicita explicit această conversie. Această conversie nesolicitată în mod explicit se numește conversie implicită.
Conversiile implicite, mai ales de la text la număr sunt riscante într-un mediu multicultural, cum sunt computerele din România, unde nu putem fi siguri de semnificația virgulei. Din acest motiv, se recomandă conversiile explicite, adică cele în care indicăm lui Excel că dorim un anumit tip de date. Aici, pentru a evita problemele vom transforma conținutul celulelor din L, calculat cu formula explicată până aici, în numere propriu-zise, prin trimiterea rezultatului deja existent către funcția VALUE():
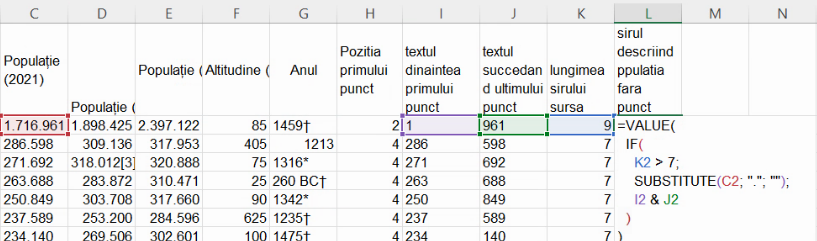
Funcția
VALUE()primește un singur argument, pe care funcția îl va transforma în număr. Dacă argumentul nu poate fi interpretat de Excel ca număr,VALUE()va returna eroare.Funcția
TEXT()primește un singur argument, pe care funcția îl va transforma în șir alfanumeric.
Extindem formula la restul coloanei:
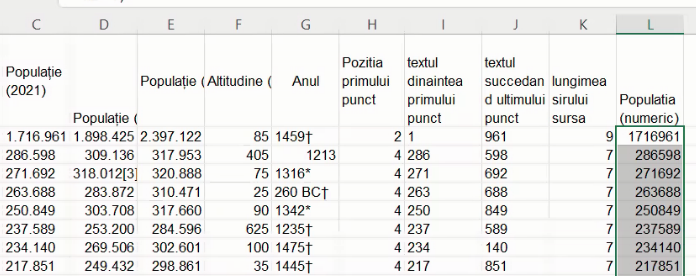
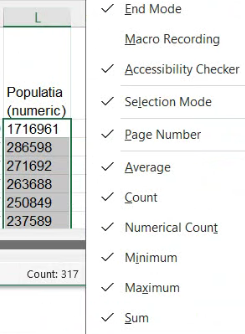
Alinierea la stânga sugerează că avem valori numerice în coloana L. Pentru a verifica ne putem folosi de Quick Aggregates, Selectăm coloana L, și citim în bara inferioară câte celule au conținut (318), respectiv câte conțin numere (317):
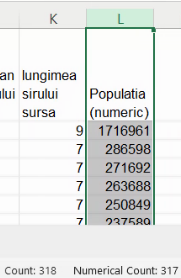
Avem din nou o singură celulă cu conținut non-numeric, L1, adică titlul coloanei. Cu acest fișier, putem trece la analiza statistică a variabilei Populație (numeric).
Funcția recentă NUMBERVALUE() face simultan conversia la numeric, dar și trecerea de la virgulă zecimală la punct zecimal șamd. Fiind un adaos relativ nou la Excel, va trebui să va asigurați, înainte de a o folosi, că și ceilalți utilizatori ai foii de calcul au o versiune de Excel suficient de nouă, încât să poată calcula NUMBERVALUE().
Conversia listei hipertext la coloană Excel
O altă sursă de date utilizată în exemplele de la seminarul de statistică constituie lista orașelor. În România, localitățile urbane pot fi orașe sau municipii, deci legal, un municipiu nu este un oraș. Vom folosi o listă a orașelor de pe Wikipedia, de la https://ro.wikipedia.org/wiki/Lista_ora%C8%99elor_din_Rom%C3%A2nia#Lista_alfabetic%C4%83_a_ora%C8%99elor_din_Rom%C3%A2nia_(f%C4%83r%C4%83_municipii), corectând eventualele probleme de import. Copiem din browser această listă:
Rezultatul poate fi unul neplăcut estetic, dar și incorect pentru statistici:
Vom elimina hiperlinkurile și formatul neobișnuit, ca mai sus, însă rezultatul nu va fi o listă de nume de orașe utilizabilă, din cauza persistenței numerotării:
Pentru a extrage numele orașului din coloana A, va trebui să folosim MID(). Acestă funcție este asemănătoare cu LEFT(), în sensul că va extrage un număr de caractere dintr-un șir alfanumeric, numărându-le de la stânga la dreapta, însă extracția nu se va face neapărat de la începutul șirului alfanumeric procesat. Mai precis, va exista un alt treilea argument, în plus față de cele două ale lui LEFT(), care va preciza de unde începe extracția.
Funcția
MID()primește trei argumente, un șir alfanumeric din care să extragă, poziție de unde începe extragerea, și un număr de caractere să care să le extragă pornind de la acea poziție. De exemplu,MID("statistica", 3, 2)returnează “at” (două caractere începând de la poziția a treia).
Pentru rândurile 1-9, unde avem o cifră, urmată de punct, apoi de un spațiu inutile, va fi necesar să începem selecția după aceste trei caractere, de la poziția 4. Pentru rândurile 10-99, unde vom avea două cifre, un punct și un spațiu inutile, vom începe selecția de la poziția 5. Ca regulă generală, selecția va începe de la poziția punctului plus 2.
Pentru lungimea șirului de caractere extras, am putea folosi LEN(A1) - FIND(""."; A1) - 1, care va returna 5 pentru “1. Abrud”, 6 pentru “2. Agnita” etc. Din fericire, al treilea argument al lui MID() nu este testat pentru validitate. Vom scrie deci formula:

În această formă, MID() va încerca să extragă 99 de caractere, dar se va mulțumi cu mai puține, oprindu-se la finalul șirului pe care îl procesează.
Toleranța pentru valori absurde este o provocare la învățarea funcțiilor Excel. Dacă am fi folosit 99 ca argument doi (poziție de la care să înceapă selecția), MID() ar fi returnat eroare, nefiind capabil să înceapă selecția cu poziția 99. Dar valoarea absurdă din argumentul 3 este tolerată, și chiar utilă.
Extindem formula:

Am obținut în coloana B o listă a numelor de orașe, fără caractere suplimentare. Un rezultat similar este uneori obținut cu Paste special, o opțiune din meniul de sub butonul Paste. Cu această listă, putem trece la secțiunea următoare.
Construirea unei variabile dihotomice pe baza a două liste
În secțiunile precedente am obținut o listă de localități urbane și o listă de orașe. Aces exemplu pornește de la un fișier în care se găsesc ambele tabele, în foi de calcul separate. (De exemplu, puteți copia lista orașelor într-o foaie nouă din fișierul cu lista localităților.)
Putem să folosim informația din cea mai recentă listă, cea a orașelor, pentru a crea o variabilă dihotomică, cu variantele “oraș” sau “municipiu”, în tabelul ce include toate localitățile. (Reamintim că legal o localitate poate fi doar oraș sau doar municipiu, niciodată ambele.) Funcția care va duce greul acestui calcul, comparând cele două mulțimi este MATCH().
MATCH() primește trei argumente, cel de-al treilea modificându-i mult comportamentul. Aici vom folosi doar varianta cu al treilea argument 0, pe care versiunile recente de Excel îl descriu în popup ca semnificând "Exact match", adică potrivire perfectă

Funcția
MATCH()caută o valoare, precizată de primul argument, într-un șir de valori, precizat de al doilea argument. Dacă al treilea argument este 0, funcția va returna prima poziție din șir care reproduce identic valoarea primului argument. De exemplu,MATCH("are", {"Ana", "are", "mere"}, 0)returnează 2.În cazul căutării exacte,
MATCH()va returna eroare dacă nu găsește ce caută. De exemplu,MATCH("pere", {"Ana", "are", "mere"}, 0)returnează eroare.În căutările inexacte,
MATCH()va returna poziția unde ar putea intra valoarea căutată. De exemplu,MATCH(23; {0;10;20;30}; 1)returnează 3, fiindcă 23 ar intra în șirul ordonat acolo unde este 20, adică s-ar potrivi în locul celui de-al treilea număr din șir. La căutare inexactă, nu se mai returnează erori, și deci este necesar ca șirul de valori din al doilea argument să fie ordonat pentru ca rezultatul luiMATCH()să fie util. (MATCH(23; {0;10;0;-10}; 1)va returna un număr, pentru că nu mai sunt returnate erori. Dar cel mai probabil acel număr returnat este inutil.)
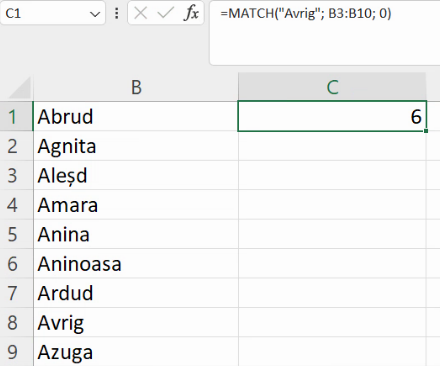
Desigur că nu vom folosi MATCH() ca în exemplele de mai sus, introducând între argumente o listă cu nume de orașe. Pentru al doilea argument, vom folosi lista celulelor cu nume de orașe. De exemplu, unde este Avrig în lista orașelor?

Răspunsul, 8, ne va spune unde se află celula cu textul “Avrig” în interiorul listei de celule de pe coloana B. Valoare returnată nu se referă la poziția în foaia de calcul – nici la linie, nici la coloană -, ci doar la poziția în regiunea indicată de al doilea argument. De exemplu, cu alte regiuni specificate la al doilea parametrul, același Avrig din A8 va fi descris ca fiind în altă poziție.

Reamintim că regiunile sunt de regulă descrise cu coordonatele colțului stânga sus și dreapta jos, separate cu “două puncte”. Regiunea
A1:B3va fi grupul de celule A1, A2, A3, B1, B2, B3. AbreviereaB:Bdescrie toate celulele de pe coloana B, de la B1 la B1048576. Abrevierea5:5descrie toate celulele de pe lina 5, de la A5 la XFD5.MATCH()nu poate cauta decât pe o linie sau o parte din linie, sau pe o coloană sau o parte din o coloană.
Dar Praga unde se află în lista orașelor?
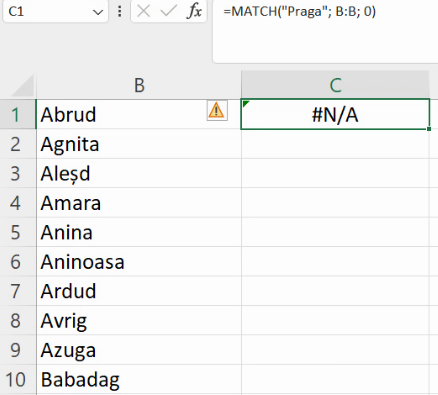
Eroarea indică absența Pragăi din lista orașelor. Prin urmare, prezența sau absența erorii indică prezența / absența valorii căutate în regiunea indicată cu al doilea argument. Putem construi un test logic pentru prezența erorii cu ISERROR().
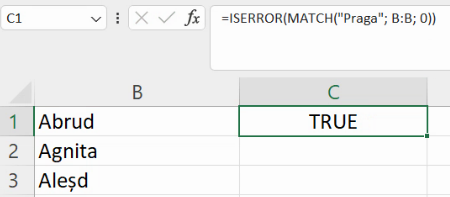
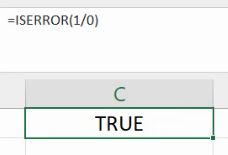
Funcția ISERROR() primește un singur argument, și returnează TRUE dacă calculele necesare acelui argument conduc la o eroare.
Cele mai simple erori sunt cele aritmetice, precum împărțirea la zero sau extragerea logaritmului unui număr negativ.

Putem deci, cu IF() și ISERROR() să construim o expresie care returnează “municipiu” sau “oraș”, în funcție de prezența / absența numelui în lista de nume de orașe:
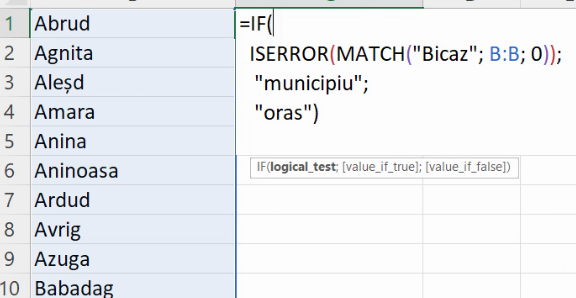
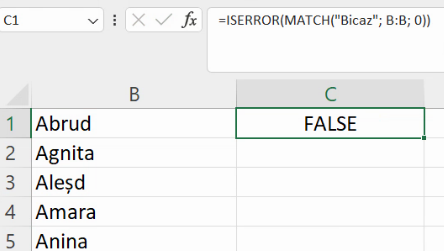
Ultimul pas este transferarea acestei formule de pe foaia de calcul ce enumeră orașele la foaia de calcul ce descrie toate localitățile urbane. Revenim la foaia de cu lista tuturor localităților, și vom înlocui “Bicaz” cu fiecare nume de localitate din coloana A:
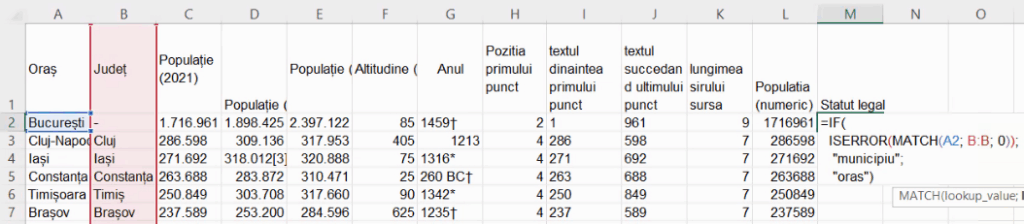
La mutarea formulei în altă foaie de calcul, se va pierde înțelesul celulelor descrise ca adresă. Așa cum vedeți în imaginea de mai sus, B:B nu mai indică coloana B din foaia de calcul cu orașe, ci coloana B din foaia de calcul curentă (evidențiat cu roșu). Pentru a redresa situația este necesar să specificăm care din foile de calcul deține celulele relevante. Aici, putem denumi foaia de calcul cu nume de orașe “orase”:
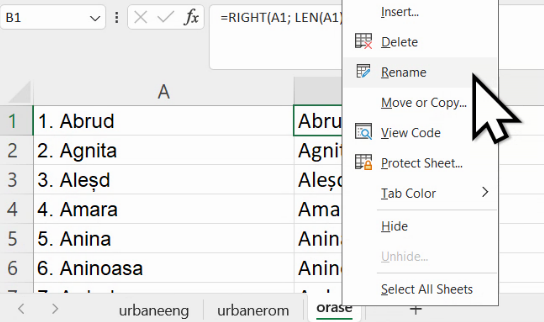
Numele foii de calcul poate fi folosit în formule cu semnul exclamării. Aici, vom scrie orase!B:B pentru a specifica coloana B din foaia de calcul numită orase.
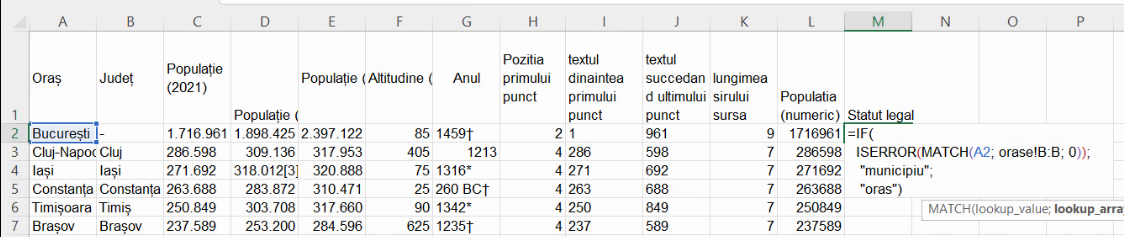
Extindem formula până la baza foii de calcul pentru a obține o variabilă dihotomică:
Această formulă va aloca fiecare unitate statistică (localitate) unei categorii sau celeilalte, neexistând localități în ambele categorii sau fără categorie, ceea ce definește o grupare. Cu acest fișier, putem trece la analiza descriptivă a noii variabile dihotomice.
Variabilă surogat
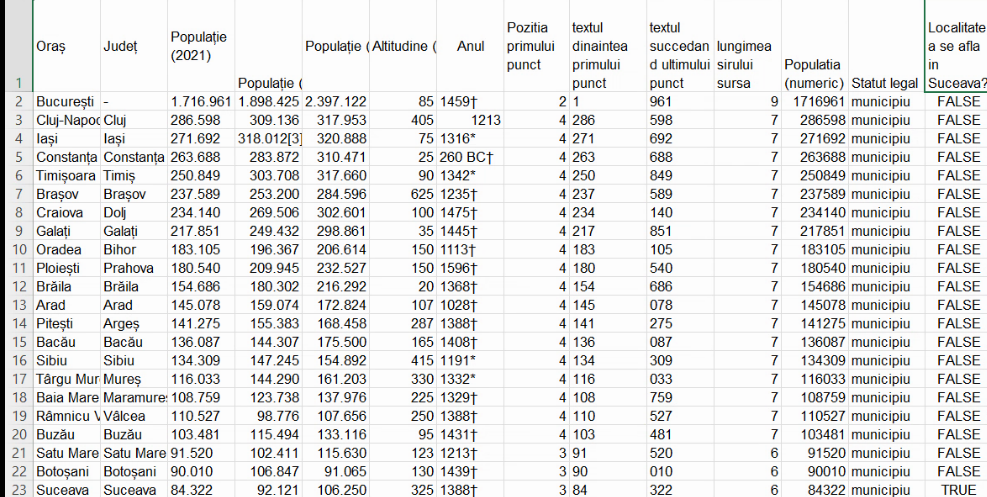
Variabila surogat (dummy) este variabila dihotomică care descrie cu 1 și 0 valorile de adevăr ale unui test, aplicat fiecărei unități statistice, permițându-ne unele operații de sintetizare a informației din tabel. Să considerăm testul “localitatea este din județul Suceava”. Vorbim în primă instanță de compararea a două șiruri de caractere, “Suceava” și valoarea caracteristică din coloana B:

Extinderea formulei produce o coloană de valori logice, adevărat sau fals.
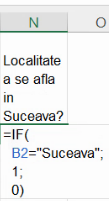
Pentru producerea de 0 și 1, va fi nevoie de utilizarea acestor valori logice cu IF():
Extinderea acestei coloane produce valorile variabile surogat. Mai mult, în bara inferioară, la Quick statistics vom avea deja cele mai importante date:
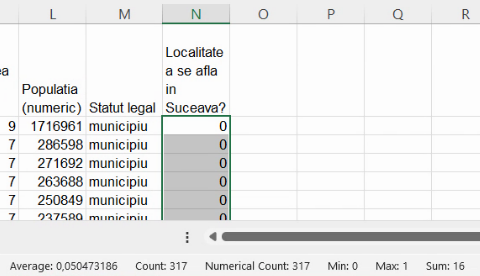
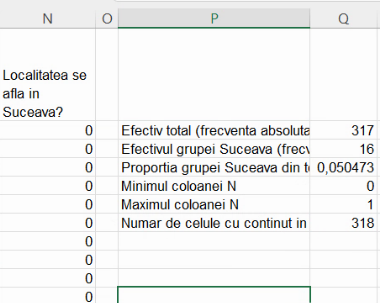
Conform imaginii, variabila surogat are 317 valori caracteristice (Numeric count), între 0 (Min) și 1 (Max). Suma (Sum) valorilor variabilei surogat este 16, indicând că testul a fost adevărat pentru 16 unități statistice. (Cu alte cuvinte,16 localități aparțin submulțimii de localități sucevene, 16 fiind efectivul submulțimii de localități caracterizate de apartenența la jud. Suceava.) Atât 16, cât și 317 sunt frecvențe absolute, nefiind calculate în raport cu alte numărători sau măsurători, ci doar în grupul pe care îl caracterizează (colectivitatea-țară și respectiv subcolectivitatea-județ).
Media aritmetică (Average) pentru coloana de valori ale variabilei surogat este cca 0,05. În cadru profesional, spunem că, din totalul localităților din România, o proporție de cca. 0,05 corespunde localităților din județul Suceava. În comunicarea cu publicul larg vom transforma în procente, conform convenției că “%” nu este altceva decât o abreviere a lui “înmulțit cu 1/100”. și deci vom spune că, din totalul localităților din România, o proporție de cca. 5% corespunde localităților din județul Suceava. Ambele variante (0,05 și 5%) sunt rezultatul împărțirii efectivului de submulțime (16) la efectivul total (317), caracterizând submulțimea suceveană în raport cu alte mulțimi (aici, în raport cu efectivul mulțimii mai mari, de localități românești). Din acest motiv, spunem că 0,05 și 0,05 sunt frecvențe relative.
Întrucât Quick stats pot fi activate / dezactivate pe fiecare sistem, și nu pot fi folosite în calcule, ar fi indicat să le calculăm cu formule, în celule. Am setat Excel să arate formulele în locul rezultatelor (hotkey Ctrl+`), pentru a ilustra care sunt calculele:
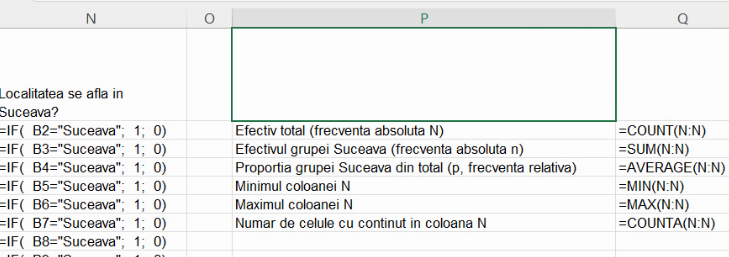
COUNT(),MIN(),MAX(),SUM()șiAVERAGE()primesc oricâte argumente, fie ele regiuni din Excel, valori literale sau șiruri literale și returnează efectivul de valori stocate de Excel ca numere, minimul lor, maximul lor, suma lor și media aritmetică calculată cu pondere egală pentru toate numerele. De exemplu, dacă în celula A1 avem 1, în A2 avem 2, iar în A3 avem 3,AVERAGE(A1, A2:A3, 4, {5, 6, 7})va “dezasambla” grupurile, și va returna același număr caAVERAGE(1,2,3,4,5,6,7).
COUNTA()returnează numărul de celule care au conținut, de orice fel, numeric sau nu.
Rezultatul formulelor de mai sus este:
Pentru a obține frecvența relativă ca procent nu este necesar vreun calcul, ci doar schimbarea tipului de dată din acea celulă, de regulă posibilă cu un buton la îndemână
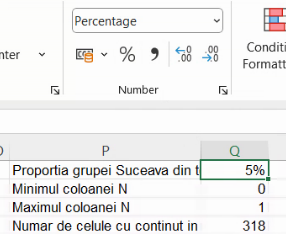
Dacă butonul nu este vizibil, puteți trece de la număr obișnuit la procent și invers, și cu dropdown-ul ce deschide setul de butoane Number:
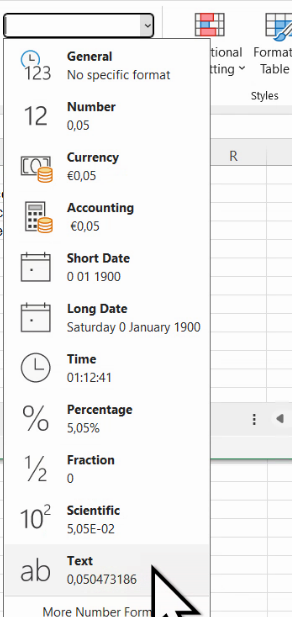
Trecerea de la Number la Pecentage nu va schimba valoarea numerică a acelei celule, ci doar modul în care este afișat. Pentru detalii și mai fine, puteți deschide dialogul Cell, la rubrica Format number, cu ajutorul butonul ce închide secțiunea Number din ribbon:
Dialogul Format cells vă va permite o serie largă de modificări ale afișării, fără afectarea valorii numerice în sine:

Relevant pentru calculele voastre din ASE va fi notația științifică, ce cuprinde două numere, separate de litera E:

Imaginea de mai sus arată că 0,0505 se va scrie în notație științifică. 5,05E-2. Ca regulă generală, un număr notat științific ca xEy este egal cu x înmulțit cu 10y. Aici, 5,05E-2 este 5,05 înmulțit cu 10-2. Notația științifică este utilă pentru numere foarte mari sau foarte mici, ca 6,02E23 sau 1,6E-19.
Rezultatul acestei secțiuni se găsește în fișierul acesta.
Discretizare
Discretizarea (binning) este transformarea unei variabile cantitative într-o variabilă calitativă, ceea ce ulterior ajută la grupare. Vom discuta două exemple, care ilustrează cum, de regulă, dar nu întotdeauna, noua variabilă este ordinală.
Să considerăm seria de date despre localitățile din România, în oricare din cele două variante de mai sus (cea derivată din Wikipedia română sau cea engleză):
Vom definit, pur convențional, ca fiind localități mari, localitățile cu cel puțin 200 de mii de locuitori. Dintre cele rămase, vom numi mijlocii cele cu cel puțin 50 de mii de locuitori. Implicit, există și o categorie de localități mici. Vom crea noua variabilă în coloana I, cu IF(). Dar avem trei tipuri de localități, iar IF() returnează doar două valori – una pentru adevăr și cealaltă pentru fals. Vom începe deci să construim expresia cu un IF() inițial:
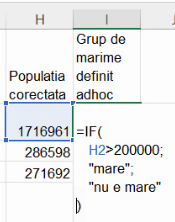
Valoarea “nu e mare” descrie o clasă, care cuprinde două grupe, “mica” și “mijlocie”. Putem deci înlocui “nu este mare cu un IF(), care să distingă între aceste două cazuri:
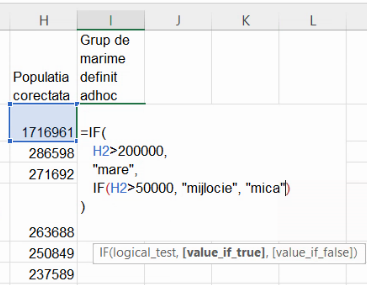
Această formulă este suficientă pentru a obține toate cele trei variante statistice posibile. Extindem formula până la baza tabelului:
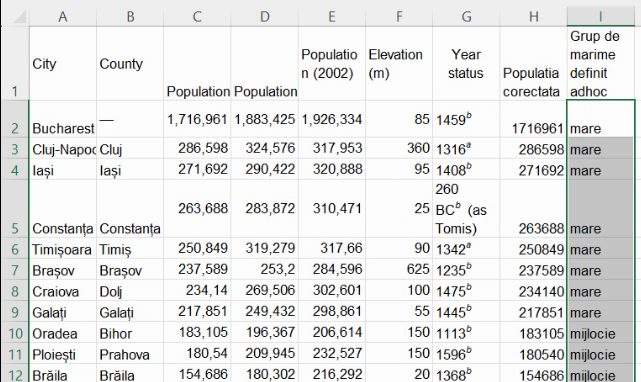
“Mic”, “mijlociu” și “mare” au o ordine clară, independentă de limba sau cultura în care acestea ar fi traduse / transpuse. Variabila derivată “Grup de mărime” este deci ordinală. Fiindcă formulele returnează mereu una și doar una dintre aceste trei descrieri pentru fiecare din localitățile din table, putem spune că am făcut o grupare.
Vom analiza cantitativ variabila ordinală de mărime din fișierul acesta în alt capitol. Tot acolo vom discuta metode de a crea eficient un număr mult mai mare de grupe bazate pe intervale.
Discretizare cu rezultat nominal
Similar cu gruparea ad hoc de mai sus, putem grupa localitățile urbane în grupe de formă de relief, numite “campie”, “deal”, “munte”. Am hotărât arbitrar la ca dealul să înceapă de la 200 m, iar muntele de la 600 m altitudine. Astfel, în primă instanță, aș putea repeta procedeul de mai sus, cu două IF()-uri imbricate (nested, inserate unul în celălalt):
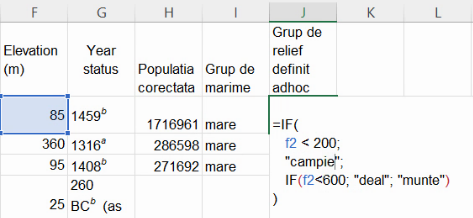
La extinderea formulei, totul pare bine:
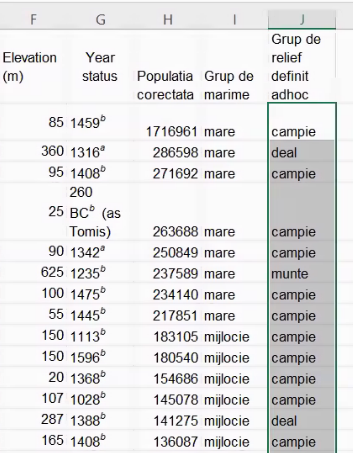
Însă inspecția mai atentă indică o oarecare creativitate din partea Excel:
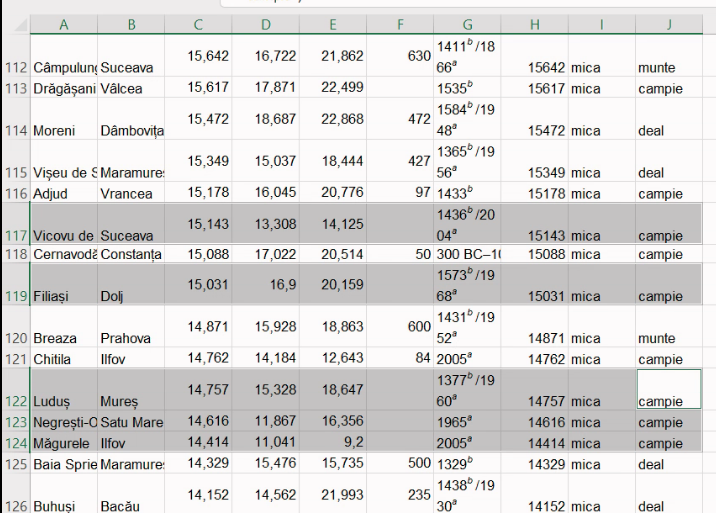
Localitățile unde tabelul Wikipedia nu preciza altitudinea au fost trecute automat în grupa “campie”.
Excel consideră celula vidă ca fiind zero, atunci când o valoare numerică este necesară pentru acea celulă. Mai mult, numerele sunt și forma în care Excel stochează datele din calendar și valorile logice. În acest context, zero reprezintă valoarea internă a lui
FALSEși a lui1 ianuarie 1900. Deci, dacă A1 este o celulă goală,IF(A1, "adevar", "minciuna")returnează “minciuna”, iarYEAR(A1)returnează 1900.
Înainte de a verifica cum se compară altitudinea cu 200 sau 600, va trebui să testăm întâi dacă în coloana F avem o altitudine. Acest test se face cel mai corect cu ISNUMBER().
Funcția
ISNUMBER()primește un singur argument și returnează o valoare logică,TRUEdacă argumentul este număr șiFALSEdacă nu.Pentru a combina valori logice, Excel oferă
AND(),OR()șiNOT(). De exemplu,NOT(2+2=4)returneazăFALSE.Fără a ști valoarea celui de-al doilea argument, știm sigur că
AND(2+2<>4, A2=6)va returnaFALSE, deoarece prima propoziție este falsă. Similar,OR(2+2=4, A2=B2)va returnaTRUE, deoarece prima propoziție este adevărată. Totuși, spre deosebire de intuiția voastră și de alte medii de calcul (inclusiv R), în Excel,AND(2+2<>4, 1/0 = 4)va returna eroare, Excel calculând și al doilea argument, chiar dacă aparent acest calcul era inutil.
Vom plasa testul ISNUMBER() la exterior. Dacă nu avem număr pentru altitudine pentru o localitate, vom declara grupul de relief pentru ea ca fiind “neprecizat”. Astfel avem un set de trei IF()-uri imbricate:
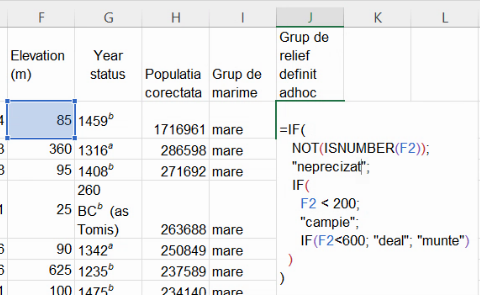
Rezultatul extinderii formulei modificate va fi o coloană, pe care fiecare localitate va fi descrisă cu un singur calificativ dintre cele patru posibile (“campie”, “deal”, “munte”, “neprecizat”).
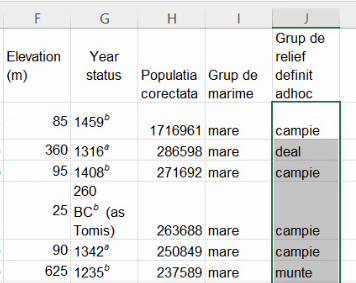
Am realizat din nou o grupare, deoarece am definit și patru submulțimi ale colectivității, cu fiecare element inclus în o singură submulțime, și niciun element rămas în afara acestor submulțimi. Însă noua variabilă nu este strict ordinală, pentru că trei dintre categorii ar putea fi ordonate, dar nu există un loc potrivit în acea ordine și pentru “neprecizat”. Prin urmare, am creat o variabilă nominală. Vom analiza cantitativ datele din această grupare în alt capitol.
Discretizare cu rezultat descriptiv pentru fiecare interval
Vezi următorul capitol.